1. Introduction
Table of Contents
- 1. Dynamic Web Sites
- 1.1. Why Dynamic Web Sites?
- 1.2. What's required?
- 1.3. What's available?
- 2. Zope Overview
- 2.1. A web application server framework
- 2.2. Simplified architecture
- 2.3. Acquisition
- 2.4. Security
- 2.5. Scalability
- 2.6. Independence
- 2.7. User community
- 3. About the book
- 4. About the author
Welcome to "Building Dynamic Web Sites with Zope"! The fact that you look at this book indicates your interest in web sites, either Intra- or Extranet sites. Maybe, you have already build one or even many web sites. That would not be bad, as lots of aspects are essential to build any successful web site, be it static or dynamic. Think of a consistent and pleasing design, good navigation elements, an adequate mixture between graphics and text, between fun and information, a style matching the expectation of your audience, presenting the right content for your visitors. This requires lots of talents (or several people that contribute different talents), some of which I do not have. For example, I would not expect me to be a good (graphical) designer. This is one reason why this book must restrict itself. The book will deal with aspects that are new or especially important for dynamic web sites in contrast to static web sites. You will not learn much about rules or tools for graphical web site design, for example. However, I hope, you will learn much about dynamic web applications, about dynamic generation of Web pages, about integration between the Web and backend components such as databases and mail services. The main focus will be, how you could do that with Zope, the Z Object Publishing Environment. Zope is an advanced web application server framework. Such a framework provides concepts, tools and architectural support for the implementation of web applications and thereby dynamic web sites. Why did I choose Zope? There are two main reasons. First, Zope is open source. This allows me, a curious person, not only to see that something works but to understand how it works. Second, there are no investment costs (beside time) necessary to use Zope. This allows me, an avaricious person, to learn, to explore and to gain experience without a large initial investment. In fact, these two reasons have been the initial motivation to look closely at Zope. This close look soon turned into real excitement: excitement about how easy interesting applications can be build with Zope, excitement about the active Zope user community that built hundreds of interesting and useful Zope components, excitement about the integrative power of Zope. Zope incorporates almost everything (in technical terms) I am and have been interested in in the past: object orientation, databases, transactional systems, publishing, web protocols, XML, distributed authoring, workflow systems and integration, E-commerce, portals...
The purpose of this first chapter is to provide you with an impression what you can expect from the book. It should allow you to decide whether it may be worth to look at the other chapters. We start with an overview of some aspects of dynamic web sites (surely, it will not be complete). Then we will have a closer but still superficial look at Zope, its main features. You will then be introduced in the book idea, how the book should unfold, what its aims are and where it will restrict itself. Finally, you will learn something about me, the author, and my motivation to write this book.
1. Dynamic Web Sites
What are Dynamic Web Sites? I use a quite simplistic and very general answer to this question: a dynamic web site is a site which uses dynamic web pages. A dynamic web page is a page that is not pre-produced but generated during the publishing process. Let's contrast this with its opposite, a static web page. A static web page is produced once, either manually authored or generated during an automated production process and then stored as a file in the file system. If there is a web request for the page, the web server fetches the file and delivers it virtually unprocessed to the web browser. This is a very robust and efficient process. The web server can be very simple, as it needs only to translate the request URL (Universal Resource Locator), i.e. the specification which page has been requested, into an access path to the file, open it and transfer its content back to the browser. This simplicity was one of the major factors for the success of the WWW. Web servers could easily be build with little effort and on cheap hardware. What's wrong with static web sites? Why should someone want to build a dynamic site? There are several reasons for this which we will now examine in detail.
1.1. Why Dynamic Web Sites?
1.1.1. Modularization
The information technology often starts with simple, i.e. easily implementable, solutions. Their success leads to an overwhelming mass of entities which soon requires improvements to the basic solutions to organize and manage this new wealth of possibilities. This adds complexity to the simple solutions and sometimes requires completely new solutions. Something like this is currently happening to the web. Its success produced hundreds of millions of web pages interlinked with one another. It is very easy to create a web page and it is easy to maintain a set of, say, some dozen web pages. But it becomes a nightmare, when one wants to maintain hundreds or thousands of web pages. There are some standard recipes to tackle this form of complexity:
| modularize and factor out common aspects |
| separate different concerns, such as e.g. content, logic and presentation |
| reuse existing components whenever possible |
| parameterize components and make them configurable to improve reusability |
Example 1.1. Consistent presentation style
Suppose you want to present a set of related web pages in a consistent style: same background, same fonts and font properties, same typographical rules, same color scheme. You can achieve this through a separation of content and presentation. You have one presentation module, usually called a style sheet, which specifies the presentation details. You have several modules with the content for your pages. All pages reuse the same style sheet and thereby get their consistent presentation. If you decide that the presentation must change, e.g. because your marketing consultant told you that the color scheme or the fonts are no longer modern, then you make modifications at only one place, in your style sheet, rather than in all your individual web pages. That's the way, modularization helps you. Decide and modify at one place and see the effects automatically at many places.
Example 1.2. Uniform navigation elements
When you maintain a larger web site, you will probably want that your visitors can easily navigate around. It helps immensely, if your visitors see uniform navigation elements on all your pages. It is even better, when these navigation elements are context sensitive, i.e. are aware of the current visitor location. This again calls for a component that implements the navigation. As we saw in the presentation style example, all pages should use this component to get the required uniformity. If the navigation should be context sensitive, then the navigation component must be configurable to react to the different contexts. The separation of the navigation into a single component will localize changes to a single place when the site structure is modified. It would even be better, if the navigation could automatically adapt to the site structure.
We have seen that modularization can help you to increase consistency and uniformity. We also saw, that often modifications need to be done at only a single place rather than many places. This increases efficiency and avoids errors. To make effective use of this modularization feature, you will need automatic composition support that ensures that the final pages are up to date with respect to the modules they are composed of. There are special tools that provide this support for static web pages, such as e.g. Schematext. When you made relevant changes to your modules, you can tell these tools to regenerate all your static pages. However, your static site does not change automatically but only after the pages have been recreated (you may view this as a feature). There is no need for special tools for dynamical web pages. Such pages are composed from their components automatically during the request. Changes to a component are automatically visible at the next request.
To summarize, dynamic web pages automatically support modularization, the composition of web pages out of components during publication.
1.1.2. Searching
A well structured static web site supports the exploration of its content through browsing. The home page presents of set of content categories, e.g. News, Products, Support etc. implemented as links to the entry pages for these categories. These entry pages are similarly structured with respect to the set of their sub-categories. A visitor descends through the hierarchical structure until he finds what he is looking for. This exploration form is adequate for unfocused visitors or for relatively small content domains. It becomes unfeasible for large content bases and ineffective for visitors with precise information requirements. Such cases call for an alternative way of exploration: searching. With searching, the visitor specifies what content he is interested in, usually in the form of a set of relevant keywords, and is presented with a search result overview. The overview provides a list of pages matching the query. Usually, the overview contains meta information for each page, such as title, author, size, summary. It is almost always impractical to use static pages to present such search result overviews. They call for dynamic page generation.
1.1.3. Interfacing with external systems
Suppose, you run an E-shop that indicates for each article whether it is stocked. Or you present the latest stock market values for your visitors or the latest news items. In each of these (and many other) cases, you present information that is maintained and changed by external systems, independent of your web environment. Your only chance to present up to date information is to ask the leading system for this information and build the web page dynamically.
1.1.4. Interaction
Suppose, you run a news site where your visitors can post relevant news articles. Your visitors will surely expect that they can see their articles soon after posting. This is best accomplished through a dynamic generation of the current news list.
For a high quality news service some delay may be acceptable. In fact, it is quite normal, as the contributed articles are often reviewed before publication. In such a case, the news service could be build as a static web site, too. However, a dynamic page based news service can easily be used as a discussion and collaboration forum. Longer delays between post and publication hamper such applications considerable. Dynamic page generation becomes a requirement.
1.1.5. Personalization
Visitors of a large web site may estimate high when they can personalize their view of the site: what content should be easily reachable, what content is relevant and what should not be shown at all, which layout and color scheme should be used, etc. My Yahoo! is a good example for the personalization possibilities. Personalized web sites require dynamic page generation as the visitor needs immediate feedback to his decisions to feel comfortable.
1.1.6. Push services
A site may wish to offer interesting push services. This usually requires some kind of personalization as pushing information may be felt as privacy violation when the information is unwanted. Therefore, the visitor must explicitly express his desire to receive the information. Often, I expect a wish to tailor the pushed information, e.g. with respect to the content and pushing frequency. Although the push services themselves do not require dynamic web page generation, the customization and tailoring will. And, of course, the pushed information will probably need to be dynamically generated. You may be lucky and can use the same tools and techniques for the dynamic push service generation that you use for the dynamic web page generation.
1.1.7. Summary
Let's summarize: you probably will think of a dynamic web site, when
your site may become large and you want to use modularity to ensure consistency and uniformity with reasonable maintenance effort,
your site should provide up to date information despite frequent chances in the information sources,
you need access to external data sources, such as databases, ERP systems or external web sites,
you plan to provide advanced interaction or personalization features.
1.2. What's required?
In this section, we investigate what a tool kit for dynamic web site building needs to support.
1.2.1. Powerful composition engine
We have seen in the preceeding section that a dynamic web site is essentially characterize by dynamically generated web pages. These web pages are composed out of components during the web request. It is natural that good support for this composition, a powerful composition engine, is essential for dynamic web page creation.
What do we need? Of course, it is necessary that the engine provides support for the inclusion of components into the composed web page. In order to be able to adapt to the context, a conditional generation of parts of the page is required. It allows to test conditions and decide based on the outcome whether or not to put some material into the generated text. Many encountered structures are iterative: sequences or lists, e.g. the results of a search or the options of a selection. The composition engine should provide iteration over such structures. Of course, the composition engine needs access to all information in the web request, the URL, the query parameters, the request body, and the cookies. All this information must be usable both in conditions and for inclusion in the generated site. Likewise, the engine must have access to configuration data to improve reusability and adaptability. A web request is answered by a web response. In fact, the engine is generating this response. For a normal response, the response body contains the generated web page. But there are exceptional responses, e.g. for error reports, for optimization, configuration or adaption. The composition engine, therefore, does not only need access to the request information, but must also be able to control the generated response. An abstraction facility is essential to prevent tedious repetition of primitive steps. The abstraction allows to partially assemble components into larger pre-assembled components that themselves can be used to either build the final page or even larger components. Such pre-assembled components are identified by name (as are all components). To increase reusability and adaptability, components whether elementary or pre-assembled should be parameterizable and customizable. They resemble procedures or functions in programming languages; they are templates themselves.
There are two broad classes of composition engines. The first class uses programs or functions described in a programming language as the components for dynamic page generation. The generation process can use all facilities, libraries and modules available for the language. The actual content is either embedded as constants in the programs or read form external sources, such as files. The second class uses page templates. A page template is essentially the page to be generated. It contains its structure and its actual content. However, in addition, there are embedded commands to the composition engine. During page construction, called rendering, the composition engine simply passes the literal parts of the template on to the generated page. However, it processes its commands to generate additional content. When you look at a page description, then, for a composition engine of the first kind, you will see essentially a program with intermingled page content but, for an engine of the second kind, you see a page with intermingled programming constructs.
1.2.2. High level web publishing framework
In the introductory comments I told you that the web publishing protocol, i.e. HTTP (HyperText Transfer Protocol), is a very simple, a basic protocol, and that this simplicity was key to its success. It is very easy to implement and it is not difficult to use, but its use is sometimes tedious. Today, you probably will not want to use neither HTTP nor CGI directly for the web page generation. CGI (Common Gateway Interface) was the first interface for dynamic web page generation. It separates the web server with its concerns for HTTP from the proper dynamic web page generation. CGI, too, is quite basic, easy to implement but sometimes tedious to use. Its main target have been command line interpreter scripts. Due to restrictions for command lines at the time of CGI definition, there is a split between information passed on the command line and that passed in the request body. Essentially the same information is sometimes passed as command line parameter and sometimes as part of the body. Command line parameters are encoded, request body parameters may be but need not be encoded. A good dynamic web publishing tool should hide such differences from you. It should be a high level framework that allows you to concentrate on page generation and hides the details of CGI and HTTP. All request information should be presented uniformly, whether they have been passed via the command line or in the request body, whether or not they have been encoded. The framework should activate the composition engine for the correct page and present the request information in a uniform, unencoded and easily accessible form. It should usually handle standard cases, such as Page not found errors, authentication and page protection automatically and transparently. It should, however, be possible to customize or take over these processes, if necessary.
1.2.3. Support for content, presentation and logic
We saw in the previous section that a separation of concerns is one of the key success factors to manage large numbers of entities. This separation facilitates modularization and reuse and thereby reduces the costs for creation and especially maintenance. The primary concerns for a dynamic web site are the content (what is presented), its presentation (how is it presented) and the logic to accept new content, combine existing content or trigger processes and control workflow. You will want support for each of these concerns: an easy way to author or acquire and integrate new content, facilities for a designer to create a uniform, consistent and pleasing presentation and support for programmers to implement the business logic, control workflows and interface with external components.
1.2.4. Integration with external systems
There is a growing tendency to use Inter/Intranet sites as portals to most information relevant to an enterprise or organization. Most of this information is not directly in the web publishing environment. Usually, it is in backend systems, such as external databases, ERP systems, data warehouses, customer relationship management systems, production systems or even the Internet. Dynamic web sites are especially suited for such portals, as they allow the presentation of up to date information. This means, however, they need to interface with these systems. Each may call for special protocols or interfacing strategies. Your dynamic web site toolkit should include support for the most essential external systems and be flexible enough to add interfacing components for other systems on a demand base. The same integration and flexibility demand is required for other types of applications, e.g. E-commerce.
1.2.5. Transaction support
A high end dynamic web site is a complex application where many users may concurrently access the same data and where many potential causes for problems exist. Some of these events may cause a request to be aborted. Without special precautions such aborts may result in data inconsistencies. Usually, transaction systems are used to prevent such inconsistencies. They ensure, that a sequence of operations protected by a transaction is either seen not at all or completed. In case of a problem, the transaction is aborted: all operation effects so far are automatically undone. Transactions also provide support to detect and avoid problems caused by concurrent access to the same data. Your dynamic web site toolkit should support transactions associated with web requests when your site allows modifications of potentially sensible data.
1.2.6. Security
A dynamic web site, especially one that supports strong kinds of interaction and flexibility, is much more vulnerable to attacks than a static site. When a system only supports fetching of web pages, then the chance is quite low for a hole allowing unauthorized actions. When the system, however, provides for content management through the web, then there might be flaws in the systems itself or (more likely) in the security configuration that allow modifications for unauthorized users. Therefore, build in security with a concise, clear and easy to manage security policy is essential for a dynamic web site toolkit.
1.2.7. Scalability
If you have build a good, attractive web site, the visitor number may grow rapidly. Then, it should be possible, to scale your system without a complete redesign or even the need to switch to a new tool kit. There should be few or no platform dependencies such that you can switch to newer and faster computers or more powerful operating systems. If this is not enough, it should be possible to spread the application over several separated host systems. This, too, will increase availability and fault tolerance.
1.2.8. Automation support
The dynamic web site should provide support for automation. Tasks to be automated include backup creation, database reorganization, removal of old and no longer relevant content, archival.
There is a different aspect to automation. The time when the primary use of the Internet is by visitors accessing your site by browsers may soon be over. New interaction modes where Internet sites automatically exchange information and initiate business transactions are being developed such as e.g. automated procurement systems. In such systems most information exchanges are automated via the Internet: product information (catalogs) are transfered from provider to customer. For example, if the stock for an article falls below a threshold, the customer's procurement system checks with the providers for current price and availability of the article. It sends an order, automatically processed at the providers site. The order activates a delivery workflow case at the provider. During the process, an automatic order confirmation is sent to the customer via Internet and so on. Automation via the Internet will become much more widespread than it is today. XML based formats will be used as platform independent interchange formats for this new kind of web interaction. To be open for this development, you may want to look for fine grained automation via the web and a strong XML support in your dynamic web site toolkit.
1.3. What's available?
We already mentioned the CGI, the Common Gateway Interface. It was the first framework for dynamic web page generation and separated the web server from the page generation. It is still supported by most web servers and widely used, especially for sites that generate only very few pages dynamically and want to avoid the investment in a web application server.
Meanwhile there are a lot of competing web application server frameworks around. For example: ASP (Active Server Pages from Microsoft), JSP (Java Server Pagers), ColdFusion (from Allaire, now MacroMedia), PHP/PHP3, WebObjects (from Apple), Mason, iPlanet Web application server, Zope (Z Object Publishing Environment from Zope Corporation).
2. Zope Overview
In this section, I will try to convince you that Zope fulfills most of the requirements listed in the last section. Thus, it may be worth that you have a closer look at it and continue to read this book. This is just an overview. You will find a detailed description later in the book.
2.1. A web application server framework
I said Zope is a web application server framework. What does that mean?
A framework is an infrastructure that facilitates the construction of applications for a specific domain. This means, its task is similar to a function or class library. However, while an application built upon a set of libraries usually controls input and output and determines the control flow, these tasks are taken over by the framework in a framework based application. Often a framework is already functional without any application code: tasks are performed in a generic or default way. The framework provides hooks that can be customized for application specific behavior. Hooks are activated at defined stages during the framework's task processing. The application can plug in its own function at a hook. If it has done this, then its function is called by the framework when it reaches the hook. When the function returns, the framework uses the function result in a hook specific way. Of course, a good framework provides also standard function/class libraries (and allows the use of external libraries) to facilitate the implementation of hook functions. Some of these functions can be used to call back into the framework to obtain additional information, to change its state or its configuration. Frameworks are often used for tasks that entail a huge amount of input sources or of generic subtasks. Graphical user interfaces are a typical application domain for framework use.
A web application server is the host for web applications. Usually, it is the middle tier in a three-tier architecture with the web server before and the backend systems, such as databases and ERP systems, behind the application server. The application server implements most of the user interface and the business logic and processes of the web application.
We will see lots of example web applications later in this book. To get a feeling for the Zope framework we will look at its architecture.
2.2. Simplified architecture
The figure simplified Zope architecture shows four parts, a cyan, green, brown and red one. The cyan part contains the framework's main infrastructure components. The remaining parts highlight some essential object classes whose instances are used to build the Web site. The red part symobolized application specific extensions; they define special purpose objects that can be integrated into the Web site, e.g. a shopping cart, a Weblog. The green parts are standard Zope object classes to implement standard Web site requirements. The brown part allows the application to package objects together in new classes (so call ZClasses). Their instances can then again been used in the Web site to provide high level application specific services. Let's examine the various components of the Zope framework.
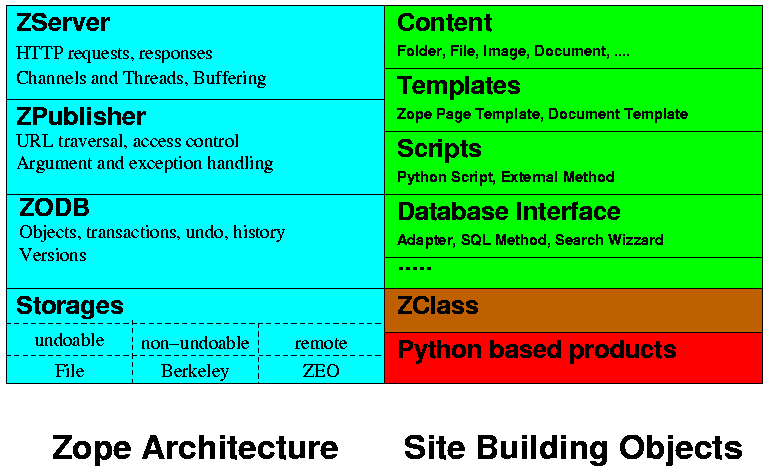
2.2.1. ZServer
The ZServer is a multi-threaded web server. It can serve several web requests concurrently and supports the Internet protocols HTTP (HyperText Transfer Protocol, the web's standard protocol), FTP (File Transfer Protocol) and PCGI (Persistent CGI). In fact, it is itself a framework[1] into which the ZPublisher plugs in. ZServer provides threads, buffers and a standard web logging facility. It receives the requests from the Internet, preprocesses them according to the CGI standard and then calls out for its application, the ZPublisher. Later, ZServer streams the response delivered by the ZPublisher to the requester on the Internet.
2.2.2. ZPublisher
The ZPublisher locates the resource addressed by the request's URL (Uniform Resource Locator). This resource may belong to the Zope framework or to the application. From ZPublisher's point of view, it is a hook that gets called. The hook function may have parameters. ZPublisher calls the function with the available parameter values. It takes them either from the request or the resource's context. It even tries to perform type conversions as only strings can be passed via HTTP but the function may need a different type. In order to provide easy access to all request information (arguments, header fields, cookies), the ZPublisher builds a request object. It further builds a response object that will later control ZPublisher's response creation. Both objects are made available for the called function (if it is interested in these objects). When the function returns, ZPublisher builds a response from the function result and hands it over to ZServer for delivery. This response building is guided by the current state of the response object which might have been modified by the function call. Usually, ZPublisher handles any errors during the publication automatically and generates an appropriate error response for them.
2.2.3. ZODB
Unlike most of its competitors, Zope does not store the web site's components in the file system. Rather, it maintains them in the ZODB (Z Object DataBase), an object oriented database. What's the advantage? In the file system, there are just two types of objects: folders and plain files. The file system defines what properties and methods these objects have. You need much more object types for your web site components: documents, images, files, folders, presentation objects, business logic objects, database queries etc. If they are all in the file system, somehow these types must be mapped to the available types. Usually, naming conventions (you surely know the use of the filename extension to indicate a content type) or location conventions are used for this mapping. The methods used to process the objects can not be maintained with the objects but must be coded inside the web application framework. This makes maintenance and extensions more difficult. It is even more difficult to add additional properties for the object types. In Zope, each of the required object types is implemented by a class. It is easy to give the class all necessary properties and define methods as needed. When an application needs specialized objects, new classes can be defined for them. Inheritance, a powerful object oriented concept, can be used to define new classes from existing base classes. The new class inherits all capabilities from its base classes. Its objects can be used wherever an object of one of its base classes could be used. Maintenance and extensibility become much easier.
The ZODB has further advantages: it is a transactional database. Modifications to the ZODB can be associated with a transaction. In case of a problem, all modifications associated with a partial transaction can be undone without compromising the integrity of the ZODB. ZODB detects when two transactions are in conflict with one another. In such a (rare) case, ZODB aborts and undoes one of the conflicting transactions and ensures its integrity. In fact, the ZODB supports two types of transactions: short living transactions used to protect the operations in a single web request and long living transactions, called versions, to support concurrent development.
The ZODB itself is a sub-framework which uses a storage module to store its content. There are several storage module types (more can easily be implemented):
- File Storage
the content is store in a file. This is the default storage.
- Berkeley Storage
the content is stored in a Berkeley database
- Oracle Storage
the content is stored in an Oracle database
- ZEO storage
the content is stored by a ZEO (Zope Enterprise Objects) server. In this way, several Zope installations can use the same content at the same time.
2.2.4. Content
Content is the most essential part of a Web site. Of course, Zope provides object classes to contain this content: files, images and templates. It also provides folders to organize the Web site into a hierarchical structure.
2.2.5. Templates
Document Template is currently Zope's main composition engine. As the name suggests, it is template based, i.e. the page specification looks essentially like a static page. Usually, it has however embedded commands to be processed during page generation. These commands normally generate additional text that is included in the page as a substitution for the command. But there are also commands that suppress page content from being included. As HTML pages are the main target, Document Template uses an HTML like syntax: new elements and specially named entities are used to embed composition commands. The set of commands is called DTML (Document Template Markup Language). All commands are identified by a dtml- prefix.
Example 1.3. Simple Document Template page specification
<dtml-var header> <h2>Simple DTML example</h2> <p>This simple example demonstrates the embedding of composition commands in HTML content. The dtml-var command is used to dynamically include the "content" of the objects header and footer at the top and bottom of the rendered page, respectively. A page's top and bottom parts usually contain essential HTML elements, as e.g. the page title and style definitions, the primary navigational elements as well as the main corporate identity elements, e.g. logo's and images. Localizing these elements in the header and footer objects provides for a consistent structure and presentation of all pages that include them.</p> <p>The dtml-var command is similar to a macro inclusion mechanism. However, what is included, is not the body of a macro definition but the "content" of an object. The object determines what its "content" is. For simple objects, such as properties, it is just their value converted to a string. Callable objects are called to determine their value. They can use acquisition to return a context dependent result. If the object is a DTML object, then a name space argument is automatically passed that gives the called object full information about the callers context.</p> <dtml-var footer>
Document Template contains commands for
- inclusion
all types of objects that can either be called or converted to a string are includable: object attributes, properties (special kind of attributes that are manageable over the Web), DTML objects (automatically rendered), methods (automatically called), request parameters.
- iteration
over any sequence, e.g. the elements of a folder, the results of a query, the properties of an object.
The command supports sorting, batch presentation and statistics.
- conditional rendering
suppresses text rendering or provides alternative text depending on conditions
- call/return
to call objects for their side effects, e.g. to update a property or send an email, and to easily control the return value.
- exception handling
usually, the ZPublisher handles all errors in a generic way. However, the application can take over control and handle (or raise) exceptions as it fits its needs.
- interactive hierarchical presentation
of hierarchical structures, e.g. the web site folder structure, hierarchical topic maps, hierarchical database relations.
The command supports interactive exploration of the structure through folding/unfolding of nodes, similar to the Microsoft Windows™ explorer.
- various extensions
either distributed with the Zope core or from third parties. These include:
When you look at the example above (and you know HTML), then you will recognize that the DTML example does not look like a complete HTML page. This is because large parts of the page are generated by the header and footer inclusions. Extracting these parts has the advantage (besides saving you typing effort) to provide for a consistent structure of your Web site. For example, the navigational elements would normally be implemented in the header and footer while the proper template is responsible for the content of this page. This is very nice, but it breaks with WYSIWYG HTML editors. They are unable to render the DTML commands. Therefor, the page they display looks completely different from that rendered by Zope. This is not good for designers. Furthermore, the editors see missing HTML components and will add them after modifications. This is not good for Zope, as then the elements inside the header and footer become duplicates. To facilitate work with advanced HTML editors, a new template engine is currently being developed for Zope: Zope Page Templates, or ZPT, for short. ZPT uses the XML namespace extension mechanism to add its composition commands as attributes to existing HTML (or XML) tags. This way, it is quite easily possible to design templates that look very similar in an HTML browser to their rendered version. In a ZPT predecessor, this visual similarity destroyed one major advantage of templates: that common parts can be extracted, maintained in a single place and used as components whereever necessary, as done in the header and footer components above. ZPT reinstates these advantages through parameterized macros. Any structurally valid part of a template can be defined as a macro by associating a macro name with it. Part of the macro's body can be defined as a parameter by giving it a slot name. Templates can use macros by referencing their macro name and provide new values for the slots, if necessary. This way, the common parts of many templates can be extracted as a macro, maintained at a single place and used as components by all the templates. If later something needs a change, just the macro definition is modified. Templates using the macro usually do not need to be touched for the modification to become effective. As HTML editors do not understand the macro mechanism, Zope performs macro expansion when the source of a page template is called for. ZPT will soon become Zope's primary composition engine and push away DTML. For new projects, you should go with ZPT.
2.2.6. Scripts
Zope provides various kinds of objects implemented in scripting languages such as Python or Perl. Their main purpose is the implementation of business logic: computing values, checking validity, enforcing rules. The different members in this category distinguish themselves by the implementation language and whether or not they can be edited through the Web. Through the Web editable objects, Scripts, are subject to Zope's access control mechanism. File system based objects, e.g. External Methods are allowed to do everything, as an intruder is expected not to be able to modify files in the filesystem.
Scripts can also be used as a type one composition engine. As they are accessible by an URL (like most Zope objects), they can be used immediately from the Web. Of course, they can be called from Document Template and can in turn use document templates to compute their content.
2.2.7. Database interface
Zope's interface to relational databases is provided essentially by database adapters and [Z] SQL methods.
Database adapters are the database type/vendor specific part of the interface. They handle and hide the differences in the call interface implementations of the various database client libraries, such that the Zope core can treat various database systems in a uniform way. There are database adapters for most major relational database systems and a generic database adaptor to access databases via ODBC.
A Zope web site is interfaced with a relational database by instantiating an appropriate database adapter object somewhere in the web site hierarchy. Such objects represent connections to a database. Their constructor asks for the necessary connection id. Database connections support execution of arbitrary SQL statements (understood by the database, of course) against the database and interactive exploration of the database's data model.
A SQL method is a Zope object that represents a template for an SQL command (in fact, it can be a sequence of SQL commands). It has an associated set of arguments and a command template. When called, the SQL method constructs an SQL command from the template, the passed in parameters and acquired context information and sends it via an associated database connection object to the database for execution. If the SQL command is a query, it returns the query result as a sequence object. This sequence object provides for easy access to each row and within each row to the field values.
SQL methods use Document Template for their template specification. In this context, special document template commands are available for e.g. type safe inclusion, appropriate quoting, conditional SQL operator generation.
SQL methods implement the Searchable Interface. This interface contains methods to determine the set of arguments (input parameters) and result columns (output parameters). The Z Search Interface wizard uses this interface to automatically generate a search interface. Such a search interface consists of an input form to get values for the arguments from the user and a report list to present the query results. The generated search interface can later be modified manually to fit the applications needs.
2.2.8. ZClass
Applications often consist of several related objects, e.g. an input form, an action, an SQL Method, a confirmation and an error page. If you need the application just once in the Web site, such a set of related objects is easily implemented inside a folder. If you need it several times, the folder based solution rapidly becomes unfeasible, as it would introduce lots of redundancies. If you want to change your application, you must visit each such folder and apply your changes. That's where ZClasses come in. From the user's point of view, a ZClass is a container for properties and methods. Properties define the state for the class' instances, the methods their behavior. The methds are arbitrary (site building) Zope objects. Thus, it is quite easy to lift a folder based application into a ZClass: just make the related objects methods of the class. Then, whenever, you need an instance of your application, you instantiate your ZClass. If your application should change, you change your ZClass, all its instances will follow automatically.
ZClasses can be easily constructed through Zope management interface, i.e. through the Web. They provide an essential tool for packaging and customization.
2.2.9. Python based products
When new functionality becomes necessary that can not (easily) be obtained through combination of existing Zope objects, then the development of a Python based product provides an alternative. Such a product is implemented in Python, can use the extensive Python library and all of Zope's infrastructure to implement new site building classes. One integrated into Zope by placing the product into Zope's Products folder, instances of the defined class can be instantiated anywhere inside the Web site where their services become necessary. Products can do almost everything. Zope.org contains more than 400 contributed products for all kinds of tasks: e.g. user management, content objects, presentation, integration, feedback etc..
2.2.10. Application
A Zope application consists of a set of interrelated objects organized in a hierarchical structure. Each object is an instance of an object class. Some classes are part of the Zope core, e.g. Folder, DTML Documents, Z SQL method, database adapters. Other classes are defined in components that are installed separately, so called products. Then, there are classes defined by the application itself. These classes are objects at the same time, instances of the class ZClass.
A typical Zope application is build via Zope's Web management interface by instantiating objects at appropriate places in the hierarchical structure. The management screen for a folder contains a select box with all object classes, that are available for the current user in this folder. When the user selects a class, its constructor is called. It asks for all necessary parameters to instantiate the object and adds it to the folder.
2.2.11. Extensions
Zope is a very flexible and easily extensible framework. Extensions are possible on different levels: by defining ZClasses, through external methods and through Python based products.
A ZClass is a class that can be built through Zope's web management system. A ZClass has an associated set of properties, organized in property sheets. They contain the class instances' state. The ZClass can define default values for all properties. The class also has a set of associated methods. These are arbitrary other Zope objects, e.g. Document Templates, SQL methods, external methods. ZClass instances can use all methods defined by their class. They have its class' properties but can give them new values. If the class is changed, all its instances can immediately use the changes. Inheritance, indeed even multiple inheritance, can be used when a ZClass is being defined. Parent classes can be Zope core classes, classes defined by products provided they have been registered as possible base classes and other ZClasses. As you may have recognized, a ZClass is more a packaging than an extension mechanism.
An external method is a Python function defined in a file outside Zope in the file system. They are used to provide functionality that has not yet been build into Zope or that is Zope functionality but is dangerous to be made available in general for security reasons (e.g. reading and writing files). External methods can not be changed through Zope's web management interface.
A Python based product usually consists a one or more classes. Frequently, the product package includes document templates, icons and further elements for the various web based user interfaces. After a product has been extracted in the Products package, the product's classes become available to create new objects in the web site.
2.3. Acquisition
One of a dynamic web site's main benefits is the composition of pages out of page components that are reused over and over again. This reuse improves consistency and reduces development costs. However, it is often necessary, that page components adapt to their context. In an earlier example, we have seen that a header component can be used to build the top part of the HTML pages in a uniform way, including the page title. Of course, the page title should not be fixed by the header component but be derived from the context where the component is used. There is thus a need for easy customization and organization of the page components. Zope uses a concept called acquisition to support both requirements.
Acquisition is a difficult concept, too difficult to describe it here in detail. One aspect of acquisition implies that all properties and methods available at one point in the web site hierarchy are available everywhere below this point; they are inherited down the hierarchy. Or, to say it in a different way, any object in the hierarchy can access not only its own properties and methods but also that of its parent, grand parent, grand grand parent and so on up to the web site's root. This suggests a way for page component organization: if a component should be used by several objects, it can be put in a common ancestor. Then, by acquisition, it can be accessed by any of these objects. If a descendant redefines an inherited feature, then this redefinition takes precedence in its sub-hierarchy. This provides for easy customization. If a different page component is required in a sub-context, the sub-context can be realized as a sub-hierarchy and the specialized page component placed in the root of this sub-hierarchy, while the generic component is located further up the hierarchy[2].
2.4. Security
Any security system is concerned with authentication and authorization. Authentication determines the identity of an acting entity, authorization determines what an authenticated entity is entitled to do.
The build in Zope authentication uses an integrated user database and HTTP's basic authentication. A user in the user database is identified by a name and a password and optionally a set of Internet domains. A set of roles is associated with a user that links into the authorization subsystem.
While the Zope framework provides for built-in authentication, the application is free to provide and use its own one, either to enhance security, to add functionality/comfort or to leverage existing user databases. There are lots of third party extensions that implement cookie based authentication (which is both more comfortable and more secure than HTTP's basic authentication) or integrate with different external user databases (NT, SMB, Unix, LDAP, etc.).
Zope is an object oriented system. In such a system, you have two type of operations that need to be protected through authorization rules: accessing attributes and calling methods. In Zope, each of these operations can be prohibited (the default), protected by a permission or unrestrictedly allowed. If an operation is protected by a permission, then the user must have this permission to perform the operation. To facilitate management and maintenance, permissions are not directly associated with users. Instead, they are associated with roles. Each role has a set of permissions. This association is context specific. Thus, while the role Editor may have the permission EditArticle in the sub-hierarchy Drafts, it may not have this permission in the sub-hierarchy Published. A user has a set of roles. He may perform an operation protected by a permission, if he has a role that in turn has this permission.
Zope uses acquisition to propagate authentication and authorization information to the objects to be protected. This provides for a flexible but still manageable security configuration.
2.5. Scalability
Zope uses a multi-threaded architecture. However, due to restrictions in the thread library of its implementation language, it can not fully exploit multiprocessor systems. However, the Zope storage can be separated out from Zope and be used concurrently by several Zope processes. The enabling product is called ZEO (Zope Enterprise Objects). It consists of a server that provides shared ZODB facilities for arbitrary many ZEO clients. Standard Internet protocols are used to connect the clients with the server. Therefore, clients can run on the same or different hosts. This not only provides for high scalability but also increases availability.
Zope scalability can be enhance also by another storage module currently under development: Oracle storage. The module stores Zope objects directly in an Oracle database. Therefore, Oracle's scalability and replication facilities can directly be used.
2.6. Independence
Zope gives you a high degree of independence.
First of all, Zope is open source: you do not buy a black box but get complete sources. Therefore, you can learn how it works and extend when it might not completely fit your requirements. This is facilitated as the Zope framework is highly customizable. Most parts can be easily replaced by application specific modules. We already mentioned this for authentication and storage facilities. In fact, you do not need to buy Zope at all in order to use it. The only requirement is proper attribution, you can otherwise use it for free. There are, however, professional support options. You are not lost even if you have no or few programming resources.
Zope is mostly implemented in Python, critical parts are coded in standard C. Python is an easy to learn, object oriented, open source, platform independent scripting language with high flexibility. Its clear and simple syntax and its module and package supports makes it ideally suited for large projects. Its library provides support for e.g. flexible string manipulation, access to the underlying operating system, processing facilities for HTML, SGML and XML, implementations of all major Internet protocols. It runs on all major computing platform and operating systems.
Currently, Zope is distributed as pre-built binaries for Intel Win/32, Intel Linux 2 and Sparc Solaris platforms. It can be easily built from sources for all Unix variants. Macintosh OS 7-9 is currently not supported as Zope relies on thread support which is unavailable for those platforms.
There is another independence dimension: Zope imposes few restrictions with respect to the protocol used for Internet access. It supports HTTP, FTP, XML-RPC and WebDAV (Web Distributed Authoring and Versioning). SOAP (Simple Object Access Protocol) support is planned. Other protocols will probably be supported as they become important.
Zope allows you to export a complete site or parts thereof and reimport in a different installation. You can easily replicate and, distribute site content.
2.7. User community
Zope has a very active user group. Thanks to its open source policy, it attracts lots of people, from students to senior consultants, that are interested in how it works. They happily collaborate by
3. About the book
The book will develop a (virtual) project: the building of a demanding web portal for an artist group. The portal will
work as a standard home page to inform the general public about the group, its members and its activities,
provide advanced services to (registered) friends, such as personalized content, What's new services, discussions, personalized email notifications about essential events,
allow portal members (artists) to manage their own content,
serve as a collaboration platform with discussion board, group calendar, news services and personalized email notifications,
automatically exchange information with other artist groups,
incorporate an electronic shop[3].
As the project is developed, you will get familiar with concepts, components and programming issues. Most of them will be directly related to Zope. Others will be more general, e.g. related to general web publishing or object oriented systems.
While a successful web site must address both issues at the server as well as at the client (i.e. the browser), this book focuses on the server side. Client side issues such as Javascript, DHTML (dynamic HTML) or Java applets will be covered superficially only.
There are other Zope books around. Most notably, the official Zope book my Michel Pelletier and Amos Latteier from Zope Corporation. There is some overlap between this book and their's. Nevertheless, there may be good reasons to read them both. The official Zope book is more introductory. It tells you, e.g., details about installation and the Zope management interface. It is focused on Zope aspects and covers more general aspects of dynamic web site building only superficially. It, too, contains an interesting example: the development of a zoo site. In contrast, this book omits most introductory Zope material. It assumes that you either read the official Zope book or that you have installed Zope based on the various README files that come with a Zope distribution. The management interface is quite natural, at least when you are familiar with the restrictions (and workarounds) of HTML based user interfaces. Therefore, this book does not go into details of the management interface, either. The overlap between the two books consists in the descriptions of many Zope concepts. The presentation is different, though. While the Zope book starts with a presentation of a Zope concept and then shows how to use it, this book starts with the task and then develops a solution. It goes beyond the official book by treating other relevant concepts of web publishing in the same way as Zope concepts, e.g. HTTP concepts, cookies, sessions and basic Javascript. Furthermore, some essential components are covered, such as session management, discussion and collaboration tools.
There are several small electronic books from Beehive. They cover special Zope aspects in detail: e.g. security and user management, ZClasses, component development. I did not read them, but they may go deeper in the covered aspect than both the official and this book.
You do not need to read a complete book when you want to learn something about special Zope aspects. The Zope community has compiled a large collection of FAQ's and HowTos. At the time of this writing, there is not yet a central registry. Usually, I first search at zope.org and then look at the Zope documentation portal.
4. About the author
The section tells you a bit about me and why I write this book.
I studied mathematics at the Universität des Saarlandes, a nice university in the south west of Germany, near the French and Luxembourg borders. My diploma thesis about an algorithm for symbolic integration [Mau82] had already strong computer science elements. My PhD thesis [Mau88] treated a compiler design issue, the use of compile time abstract interpretation to optimize the execution of lazy functional programs. Later, Prof. Dr. R. Wilhelm and I wrote a book about compiler design for imperative, functional and logical programs [Wilh92].
After my PhD, I went to the industry. I was responsible for the port of the GNU C/C++ compiler suite to a microcontroller and the evolution of a small but impressive real time operating system [PXROS]. It is the only real time operating system (I know of) that does not need to lock out interrupts and therefore can react very fast to high priority interrupts.
I went then to a newspaper with a strong IT department. There, I was responsible for the development of their multi-media archive and production system, essentially a multi-media database system with strong integration into the newspaper production workflow and special archiving support. Of course, such a system must be able to publish its content via the Internet. We had developed a CGI based web gate with HTMLgen, a Python module for dynamic HTML generation. However, my colleagues needed several weeks to create a web gate for a new customer. This, obviously, called out for improvements.
Then, Zope was announced to be open source. I downloaded the documentation and noticed that it was precisely what we needed to efficiently build web gates. I learned about database adapters and within a couple of evenings' work, I had developed a database adapter for our multi-media database. After a couple of additional evenings, I had extended Zope's search interface wizard to generate an additional detailed object view and defined some new Document Template commands to support the extended search features of our database. Then, I took the new extension to my office. With it, two of our text based databases were published over the Internet within one afternoon. A colleague took over. Within one week, he not only learned Zope but also published our most demanding multi-media databases. Due to the excellent base functionality and the easy extensibility of the Zope framework, we have been able to reduce the amount of customization for a new web gate from several weeks to a few days. About two weeks of work have been necessary to achieve this. This was a very encouraging first Zope experience.
Next we build a small editorial system for a local economic magazine. The customer, an industrial association, sends us the articles by email. They are automatically converted into an XML based format and imported into a production database. This database is published via Zope to the Internet. At the same time, its content is the basis for the layout and production process. The customer accesses it via the Internet, plans the publication of his articles, makes corrections and additions. Changes are automatically marked such that my colleagues in the production can easily determine what rework became necessary by the modifications. Any modification results in a new article version. A complete version history is available, in case there should be arguments about the published article. After a magazine is printed, the articles are transfered from the production database (with very restricted Internet access) to a publishing database (with much less restricted access). Again, Zope was highly helpful to solve this problem.
Our next Zope project was really big. A multilingual portal to European tenders. The portal supports: membership management, personalized search profiles, personalized newsletters, guest book, personalized competition watch, statistical tender evaluations. The portal will finally support all 11 languages of the European Union. It provides access to 100 GB of tender information and associated indexes. Integrated is a customer relationship management system. This time, it was not just Zope and our database system. In addition to Zope, we used Oracle 8i as database, Apache as primary web server, various third party Zope components for session management, virtual hosting and localization. Because of this size and complexity, I expected some problems and decided to subscribe to the Zope mailing lists, in order to get warned about problems and to get acquainted with the forum that might help me overcome future problems. Of course, I was not only keen to get help for my problems, I was ready, too, to help other people. Thus, I became a major contributor to Zope's main application oriented mailing list.
I assume this was the reason why wrox contacted me to write a book about Zope. I felt that I would enjoy the writing of a new book, especially a book about Zope. I am really excited about Zope, its possibilities and its open source philosophy. I am also excited about Zope's user community, its motivation, its helpfulness and its competence. I like to contribute to Zope's success and the advancement of its user group. A good book would be a major contribution as there are many recurring problems caused by less than optimal documentation, misleading terms and unexpected features. Thus, I decided to write a Zope book. It should explain enough about Zope and its internals and web publishing in general that you will understand what is going on and can solve or even avoid many problems yourself. Of course, the mailing lists and IRC channels are there, if problems should remain.
[1] an adaption of the medusa web server framework developed by Sam Rushing.
[2] It is here, where the difficulties with acquisition start: acquisition does not always behave naturally for easy customization. In fact, the example above can not be handled by acquisition. We will return to this issue later again.
[3] just for demonstration. I do not expect an artist group to sell its work electronically as art is not a mass market and personal relations are essential for art trade.