3. Basic concepts
Table of Contents
- 1. Zope site building objects
- 1.1. OO preliminaries
- 1.2. Interface ObjectManagerItem
- 1.3. Interface ObjectManager
- 1.4. Interface PropertyManager
- 1.5. Folder
- 1.6. File
- 1.7. Image
- 1.8. DTML Method, DTML Document
- 1.9. PageTemplate
- 1.10. Python Script
- 1.11. External Method
- 1.12. ZCatalog
- 1.13. Database integration
- 1.14. ZClass
- 2. Web publishing
- 2.1. HTTP
- 2.2. URL
- 2.3. HTML FORMs
- 2.4. Authentication
- 2.5. Cookies
- 2.6. ZPublisher
- 2.7. Special Zope objects
- 3. Name lookup
- 3.1. DTML namespace
- 3.2. Acquisition
- 4. DTML
- 4.1. General syntax
- 4.2. Object argument
- 4.3. Commands
- 4.4. Calling DTML objects
- 5. Site management
- 6. Security
- 6.1. Permissions
- 6.2. Roles
- 6.3. Permission and role assignment
- 6.4. Proxy roles
- 6.5. Owner restrictions
- 6.6. AUTHENTICATED_USER
The last chapter made you familiar with the example project that we want to implement in this book. In this chapter, you will learn the most basic Zope concepts. This will give you a first impression, how to map various project requirements to Zope concepts. You should be warned, however: most requirements will not directly map but will need considerable work and preparation. Some of them will only become easy through the use of Zope extension components, so called products. You will learn about products in later chapters: how to integrate, configure and adapt them.
As was outlined in the introduction, a Zope web site consists of objects that belong to various object classes. Some object classes define containers. Their objects can contain other objects. Through the use of these containers, the web site gets a hierarchical structure.
Each object is identified by an id inside its container. This implies that each object has an associated sequence of ids that trace the path from the root object to this object. On the other hand, a given id sequence may correspond to a path in the hierarchy and then address an object. This is essentially what the ZPublisher does: it interprets the path component of an URL as a sequence of ids and tries to locate a web site object with the sequence. If the sequence does not lead to an object, ZPublisher returns a Not Found reply. Otherwise, it tries to call the object. This is how Zope publishes objects through an URL.
Of course, you will ask yourself, how these objects come into existence. Some of them come with the Zope installation, most prominently the root object. Others are defined in Zope products, extension components that can be installed separately. These objects are instantiated automatically during Zope's startup. Most objects, however, are created by the content manager through Zope's management interface. The management interface is a Web interface for the management of almost all aspects of a Zope web site: the creation and modification of objects. This entails user management, access control, content definition, application development as all these activities are realized through the creation and modification of objects.
As in other object oriented systems, Zope objects have (data) members implementing the object's state and methods implementing the object's behavior. An essential member subclass is called properties. These members can be created, explored and modified through Zope's management interface.
Inside a given context, objects are accessed through names. Name lookup, the resolution of a name into an object in a given context, is therefore an essential operation. Zope uses two powerful and sometimes confusing concepts for name lookup: acquisition and the so called namespace.
Zope's main task is to respond to web requests, usually through the generation of HTML pages. Zope's primary tool for this task are currently document templates. Documents templates are pages with literal text and embedded commands, defined by DTML, the Document Template Markup Language. The available commands include support for inclusion, conditional text, iteration, abstraction, exception handling and more.
Mainly because DTML templates confuse high end HTML design tools, such as Macromedia DreamWeaver, Adobe GoLife and Macromedia Homesite, a new document template engine is currently being developed (now in beta phase): ZPT Zope Page Templates. Unlike DTML templates, it is quite easy to construct ZPT templates the source of which looks very similar in an HTML browser to the rendered template. This makes them ideally suited for authoring in WYSIWYG HTML/XML editors. Due to this fact, ZPT will soon push away DTML.
Our project defines various user classes with different access rights. Zope's security subsystem will provide partial solutions for the project requirements.
This chapter will examine these aspects in detail.
1. Zope site building objects
In this section, we will look at the most essential Zope objects classes, that you can use to build your web site[4]. Each class provides some features: they can contain content, such as images, files or templates, or they can provide interesting behavior such as search support, integration with a database or mailing facilities. Whenever you need such a feature, you place a class instance somewhere in your Web site, configure and customize it, adjust security, if necessary. The instance and its features can then be used either from the Web or from other objects in your site. The latter is especially easy for objects that are in the subtree of the folder containing the instance. Due to acquisition, they can use the instance as if it were an attribute of their own. Beside the site building objects, there are other object types essential for Zope's operation. You will meet some of them later in this chapter.
We start with some OO (Object Oriented) preliminaries.
1.1. OO preliminaries
In general, an object is an entity encapsulating data and behavior. The behavior is usually defined by a set of methods, functions[5] that operate on the objects data. This data is usually implemented as a set of members. Both methods and members, together, are called attributes[6].
In many object oriented systems, objects belong to a class (or type). The class defines common attributes of its objects. Often, a class is used as a blueprint for object creation. In this case, the object is seen as an instance of the class or class instance. A class definition consists of definitions for its attributes.
Many object oriented systems do not require to list all these definitions explicitly but provide for an inclusion mechanism. It allows to include or inherit all definitions from other classes but to override definitions that do not fit. This class definition facility is called inheritance, the inherited class is called a base class of the defined class and the defined class is called a class derived from the base class. A derived class can be viewed as an extension of any of its base classes. Its objects are at the same time objects of its base classes. In this way, inheritance implements an is a relationship.
Some systems, such as e.g. Java[Java], restrict inheritance to a single class, i.e. a class can have at most one base class. We speak of single inheritance. Other systems, such as Python[Python], support multiple inheritance: a class can have arbitrary many base classes. Multiple inheritance is a powerful feature. It allows to compose classes out of class components. Each component, itself a class, implements a, usually small, special feature set. It is reused whenever a class requires this feature set. Such small components are often called mixin classes as they are designed to be mixed in rather than be used stand alone. Zope, build upon Python, makes heavy use of multiple inheritance and mixin classes. Persistence[7] and acquisition are for example implemented through mixin classes.
You can use my DocFinder product to analyze the composition of Zope's classes, determine what methods are available, how they need to be called, by what permissions they are protected and what source code documentation is available for them.
The interface concept is related to the class concept. While a class is an implementation device, it is a set of definitions, an interface is a specification device, it is a set of declarations (usually accompanied by additional descriptive text). Currently, the interface concept is heavily influenced by Java's interfaces. A Java interface is essentially a set of method signatures[8]. Java supports an inclusion mechanism for interface definitions, similar to inheritance for classes, and calls it interface extension. A Java interface can extend several interfaces, similar to multiple inheritance.
While Python, unlike Java, does not have an interface language construct, Zope makes heavy use of interfaces. There are several kinds of interfaces: for the content manager, the DTML programmer or the application programmer. Within each kind, an object usually implements several interfaces, e.g. a security interface, a property manager interface and an object manager interface. The interface descriptions can be accessed via Zope's integrated help system.
1.2. Interface ObjectManagerItem
The interface ObjectManagerItem is implemented by objects that can be managed by an ObjectManager. ObjectManager, in turn, is an interface implemented by the container like objects. Consequently, the objects we are looking at in this section implement ObjectManagerItem. It defines the common aspects of the Zope site building objects.
The interface details can be found in Zope's integrated online help system under Zope Help->API Reference->ObjectManagerItem. We will not go into details here, as the online documentation should be more current than this book can be. We will, however, note the principles.
All Zope site building objects have an id, a title and a meta_type.
The id is used to identify the object inside the containing object manager. It must therefore be unique within this context. The set of characters allowed in ids is severely restricted: they must be valid URL characters, i.e. ASCII letters or digits, _, ~, ,, . or space[9]. Moreover, they must not begin with _. All names beginning with _ are considered private in Zope, inaccessible through the web. Ids must not end in two _. This, probably, is another privacy convention, but I am not sure. Finally, some reserved names are forbidden, such as REQUEST.
For most object classes, id is an attribute. For others, however, it is a method. At many places, this distinction is not relevant; in some contexts, however, it is. This can seriously confuse programmers. Therefore, the method getId should be used to access the id.
While id is of major importance, its companion title has much less weight. It is a string attribute which may be empty. If non empty, it is used in the management interface and the default standard_html_header. The latter uses it to define the HTML page title. There are several methods combining the retrieval of title and id in different ways.
meta_type is a string attribute describing the object's type. You can use this type, when you use Zope's Find support. Find, a tab in the management interface, lets you find objects meeting given criteria. One of the most important criteria is the object's meta type.
I already mentioned that ZPublisher maps URLs onto web site objects. It is therefore natural, that Zope provides a method that returns an object's URL, the URL that is mapped to this object. This method is absolute_url.
Sometimes, you might want to take over part of the ZPublisher's normal work: locate an object based on an URL path fragment. The method restrictedTraverse does this. It takes a path, either a string with path components separated by / or directly a sequence, and locates the object that is reached from the current object along path. You will probably use this feature to access objects that are not directly accessible through a name. In Zope, all ancestors of an object and their immediate children are directly accessible by the object. For access to other objects, restrictedTraverse is often the most natural way, at least in complex cases. The restricted in the method name indicates, that Zope performs security checks along the path to ensure that you (or your Zope users) are doing only things you are entitled to do.
Unless your site uses virtual hosts (or the virtual hosting tools for a different purpose) restrictedTraverse is almost the inverse of absolute_url. Otherwise, your site can have different URLs for the same object, for example a different URL for each virtual host. In this case, absolute_url returns the correct virtual URL with respect to the current request and its corresponding virtual host. restrictedTraverse, on the other hand, uses the physical path as defined by the web site hierarchy. The true inverse of absolute_url is the method resolve_url of the request object. restrictedTraverse, on the other hand, is the inverse of getPhysicalPath, another ObjectManagerItem method. If no virtual hosting tools are used, the URLs are directly related to the physical paths in the Web site hierarchy.
The method manage_workspace returns the HTML page used to manage the object. This page is part of Zope's management interface through which objects can be created, edited and deleted, access controlled, found, changes analyzed and discarded. An object's manage_workspace generates a page with the management options which are appropriate for the object and which the current visitor has the necessary permissions for.
1.3. Interface ObjectManager
ObjectManager is the interface implemented by Zope's container like objects.
A two level selection is used to create new objects inside an object manager. This two level approach tries to minimize the danger of name clashes between different independently developed products. At the first level, the product is selected. The second level then selects one of the object constructors from this product. With this approach, problems only arise, if different products have the same name; there is no problem, if constructors in different products happen to have the same name. ObjectManager provides the member manage_addProduct to implement the product selection. manage_addProduct is a mapping object indexed by product names. manage_addProduct[product name] returns a factory dispatcher the members of which are the product's constructors. Zope's site building objects belong to the product OFSP[10].
om.manage_addProduct['OFSP'].manage_addFolder('F')create a new Zope folder with id F in the object manager om.
ObjectManager contains a set of methods to access information about its contained objects: objectIds, objectValues, objectItems. objectIds returns the ids of the contained objects, objectValues the objects themselves and objectItems a sequence of (id,object) pairs. All these methods allow an optional argument, either a single meta type or a sequence of meta types, to restrict the objects retrieved to such with one of the given meta types. An object manager exposes its contained items as attributes. A single item can simply be accessed through its id. Thus, in the context of the example above, om.F is the newly created folder. The contained items can also be accessed through subscription: om['F'] for the example. The subscription will raise a KeyError when the object manager does not contain an object with the given id. The attribute access, on the other hand, would in this case look also for properties and acquired attributes. You will use subscription, when you want to make sure, you only get a contained object.
An ObjectManager has management methods to delete, export and import items.
1.4. Interface PropertyManager
A property is a usually small piece of (meta) information associated with an object. The "meta" indicates that this information is in addition to the primary object "content"; it provides additional aspects about the object. "title", "author", "version", "publishing state" would be property examples.
A PropertyManager manages a set of properties. Properties have a type and a value. Modification or deletion of a property can be restricted. The type is from the list float, int, long, string, lines, text, date, tokens, selection, multiple selection. Properties can be predefined by an object or defined dynamically either through the web or programmatically.
Properties are either predefined or are created with the method manage_addProperty. Property ids must not start with _ and must not contain space, in addition to the restrictions spelled out for ObjectManager ids.
PropertyManager has methods propertyIds, propertyValues, propertyItems with similar effects as the corresponding ObjectManager methods. As for object managers, properties can be directly accessed through their ids. There are some additional methods to check for property existence, access its type and fetch its value or a default.
Properties are changed with the methods manage_editProperties or manage_changeProperties. manage_editProperties changes all properties. If no new value is given, the property is reset. This may be necessary for direct through the web editing, as HTTP requests do not have parameters for unchecked check boxes and empty multiple selections. manage_changeProperties, on the other hand, changes only properties explicitly referenced in its parameters.
1.5. Folder
The Folder class is Zope's most prominent ObjectManager. You use a Zope folder in exactly the same way, you use folders in a file system: to group objects in a clear hierarchy.
A folder is also a PropertyManager. This means, you can assign properties to a folder. As folders are essentially passive objects without interesting application specific behavior, these properties are usually destined for use by the folders content or help the content manager to remember essential things about the folder.
manage_addFolder is the folder constructor, used in programs to create a new folder.
1.6. File
You can place normal files into your Zope site. You might do this, if you want to make them available for download or just publish them on your site. A file can also be used as a text component for other objects that include its content at an appropriate place.
A file is created by the constructor manage_addFile. It can be created programmatically, through the management interface or via FTP. The file content is usually uploaded. The management interface does not provide a way to edit file content through the web.
Files are property managers. One special property is the so called content_type. A Content-Type is a MIME (Multi purpose Internet Mail Extension) concept, adopted by HTTP (HyperText Transfer Protocol), to indicate the content type of a message such as an HTTP response. MIME content types consist of a type and an optional subtype, separated by /. Optional, type specific arguments, separated by ;, can provide further information. Types include text, image, application, audio, video. The most essential subtypes of text are plain, html and perhaps soon xml. Its most prominent argument is charset, it specifies the character set used by the text. Subtypes for image include png, jpeg and gif. octed-stream, pdf, postscript, msword belong to the many subtypes of application. Usually, you need not to worry about a file's content type as Zope guesses it when a file is uploaded based on the filename extension. However, sometimes, the guess is wrong. In this case, you would edit the content_type property manually.
Zope's file objects are maintained in the ZODB, its object database. Usually, they are not accessible by the programs you normally use to edit or work on these files. So, what, if you want to edit them? There are several approaches. You can have a copy of the file in your file system (or download the file via your browser), modify the copy and then upload it again. Or you can use the fact, that Zope exposes the web site through FTP, the File Transfer Protocol. Depending on your platform, there may be products (which have nothing to do with Zope) that allow you to map FTP hierarchies into your file system and use the FTP accessible objects in the same way as local file system objects. In this case, you can use your normal applications for editing[11]. You can also use the Zope products LocalFS or ExternalFile to access normal operating system files from Zope. These are not file objects as described in this section, but they behave mostly as if they were.
1.7. Image
Image objects are used to manage images in your web site. It inherits from File and almost everything, we heard about files hold for images, too. There are some small differences.
When a file is included in a document template, this is called rendering, then its content is integrated into the generated page. This is appropriate for files containing small amounts of text. It would be in most cases inappropriate for image data, as HTML does not handle images this way. Instead, HTML defines the img tag for this purpose. For this reason, the rendering of an image object generates an img tag such that an HTML browser will show the image when it displays the generated page. There is also a tag method that provides for more control over the img tag generation.
1.8. DTML Method, DTML Document
DTML objects are Zope's main page templates[12]. DTML stands for Document Template Markup Language. The language consists of a set of page composition commands that use the tag and entity syntax of SGML, familiar from its use in HTML. The commands can be embedded into plain text that is included unchanged into the generated page. We will learn the details later in the DTML section.
The main content of a DTML object is a document template. When the object is rendered the DTML commands embedded in the template are executed. Each command generates some text which replaces the original command in the template. After all commands have been executed, the resulting text is returned as rendering result. According to context, it can be used for example as response page to a Web request or as a fragment in a bigger generation or processing process.
The document template commands are executed in a name lookup context, a so called namespace. It determines how the object names in the commands are resolved to objects. The two different DTML object types, DTML Method and DTML Document use different ways to construct the namespace for their document template execution. A DTML method essentially uses the calling context unchanged while a DTML document places itself on top of the context. As a result, the document template of a DTML method does not see the method but directly looks at the calling context. The template therefore behaves like a method of the calling context. This fact gives the class its name. The template of a DTML document, on the other hand, works primarily with this document object. Only, if this object (and sometimes its acquisition ancestors) cannot resolve a name, the calling context becomes relevant. There is another minor difference between DTML document and method: the former is a property manager; the latter is not, as the properties could not be accessed anyway.
DTML Document inherits from DTML Method. Both classes have the same methods to access and change the document template and to execute it. The constructors are manage_addDTMLDocument and manage_addDTMLMethod.
1.9. PageTemplate
PageTemplate, short ZPT, is the new composition engine currently developed for Zope. It addresses two issues of DTML templates: easy integration with high end design tools, such as DreamWeaver, GoLife or HomeSite, and reducing the amount of magic involved in processing the templates.
PageTemplate uses the XML namespace extension mechanism to add composition commands to complete HTML or XML documents. It uses two XML namespaces http://xml.zope.org/namespaces/tal with default prefix tal and http://xml.zope.org/namespaces/metal with default prefix metal to tag its composition commands.
TAL stands for Template Attribute Language. The name indicates that most composition commands are attached as attributes to source tags. There are commands for definitions, conditional rendering, looping as well as element, element content and attribute replacement. Most commands essentially maintain the structure of the source. This way, the source presentation in an HTML/XML viewing or editing tool can be very similar to the presentation of the final rendered page. Thereby, designers are supported in their work. On the other hand, the templates are complete HTML/XML documents. Tools are not confused by missing structural parts that are only generated at rendering time from constructs the tools do not understand.
To provide for modularity and separation of common parts, PageTemplate uses a macro expansion mechanism to compose templates from components. The macro facility uses the namespace METAL, Macro Expansion Template Attribute Language. It defines attributes for macro definition and use as well as for slot definition and the provision of slot content when the macro is used. Slots, therefore, are the macro parameters. A macro is simply a named element in a template. The same applies to a macro slot. Macro and slot definitions as well as macro and slot use are embedded in the templates.
More information about Page Templates in the readable specifications for TAL, TALES and METAL and the excellent tutorial. Background information can be found in the ZPT Wiki.
Page Templates are constructed with the constructor manage_addPageTemplate.
1.10. Python Script
A Python script object encapsulates a sequence of Python commands. The script can be called to execute the Python commands. If they return a value, this is the result used in the calling context. Depending on context, it can be used as response to a Web request, as fragment for a larger generation or processing process or it can be discarded.
The script has various ways to access different contexts. It can define parameters and bindings. Parameters allow the caller to communicate with the called Python script by providing values for the parameters. The parameters are accessed inside the script through their names and are bound to the provided values during the execution. The bindings allow to bind other kinds of context information to names and make them thereby accessible inside the script. The available contexts include:
the acquisition context of the call,
the script object itself,
the script object's container,
the caller's namespace,
the URL sub path that remains when ZPublisher hits the Python script during URL traversal.
Python scripts can use a Python subset that is considered safe in an environment where the scripts can be edited through the inherently unsafe Web medium. While almost all Python commands are available, the set of accessible built-in functions and modules from the Python library are severely restricted. There is an unrestricted variant, too: XXXPythonScript. Because an update of these scripts through the Web poses a serious security risk, they can be changed only if Zope has been started with a special environment variable.
Python scripts are created with the constructor manage_addPythonScript.
1.11. External Method
An External Method executes Python code, like a Python Script does. However, this code is not stored in the ZODB but in a Python source file in the file system. As the file system is considered much safer than the Web editable ZODB, external methods are not restricted by Zope's security system. They can access the complete Python library, all Zope packages and modules and any attribute in objects, even private ones. This makes them ideally suited to implement utilities, e.g. integration with remote systems via HTTP, XML-RPC or other protocols, maintenance work for the ZODB (upgrading objects, deleting garbage), type conversions.
External Method is much older than Python Script. Unlike the clear and flexible bindings for Python Script, an External Method gets context information in an obscure and often confusing way. While ZPublisher calls them without surprises, calling them from other contexts involves some magic. When the first parameter is called self and the method is called with one argument less than the number of mandatory arguments, then the method's acquisition parent is passed as first argument. It corresponds to the context of Python Script and provides access to the Web site context as well as to REQUEST, the object describing the current request. Often, this magic does what one expects, but if it fails, and this happens regularly if default argument values are used, many hours are necessary to understand what went wrong. As a rule of thumb: Do not trust the magic, pass self explicitely. The method this (of ObjectManagerItem) is usually appropriate for this task.
1.12. ZCatalog
ZCatalog provides Zope's indexing and search support. A catalog encapsulates a set of named indexes, a set of cataloged objects and for each cataloged object a record of so called meta data. A catalog is used to perform index based searches for cataloged objects.
When ZCatalog indexes an object, it determines index entries for each of its indexes. In a first step, it interprets the index name as an attribute or parameterless method of the object[13]. It fetches the value or calls the method to obtain "the object's value" for the index. Depending on the index type, the value is transformed into a set of index terms under which the object is then indexed. An elementary search consists always of the retrieval of all objects that are indexed under an index term. Currently, the various index types support different types of complex queries. I hope this will change in the future.
ZCatalog supports three types of indexes: text, field and keyword. A text index splits the value into words and uses each word as index term, a field index uses the value itself as index term. For a keyword index, the value must be a sequence; it uses each sequence element as index term.
A ZCatalog query is given by a mapping that maps index names (and sometimes names, derived from index names) to query specifications. The result is the intersection of all objects obtained by querying the mentioned indexes for the corresponding query specifications. If the mapping is empty (or at least does not name any of the indexes), then the result consists of all cataloged objects.
Keyword indexes are field indexes with a slightly different indexing procedure. Their search capabilities are identical to that of field indexes. A field index supports or and range searches. An or search retrieves all objects indexed under any one of a given set of values. The query specification is either a single value (in which case the or query degenerates to an elementary query) or a sequence of values to search for. A range search retrieves the objects indexed under a term from a given range. For a range query, the query mapping must map the name index_usage to a range specification. A range specification begins with range: and is followed by min, max or min:max. The query specification is again either a single value or a sequence of values. If the range specification contains min, then the minimal value bounds the range from below, if it contains max, then the maximal value bounds the range from above.
The query specification for a text index is either a single query string or a sequence of query strings. If it is a sequence of query strings, the result is the intersection of the results for the single query strings[14]. The query string is interpreted as a query expression that consists of query terms optionally combined with query operators and, or, andnot or ... (near) and optionally grouped with parenthesis. A query term is usually a word or a phrase. A phrase is a sequence of words enclosed in ". Phrases are transformed into near searches of the containing words. The catalog delegates all word handling to a Vocabulary, also called Lexicon. If the catalog's vocabulary supports wildcards, then the query terms above can contain wildcards. In this case, they are expanded into a sequence of words (without wildcards) combined with or. If an optional operator has been omitted, the or operator is automatically inserted. The query is then executed from left to right, respecting grouping and interpreting the operator in the natural way. Difficult? Let's look at some examples:
Example 3.2. TextIndex query expressions
- tree
searches for objects indexed under tree
- tree bush
searches for objects indexed under tree or bush
- tree and bush
searches for objects indexed under both tree and bush
- tree and not bush
searches for objects indexed under tree but not bush
- "holy tree"
this is a phrase. It searches for objects indexed under holy and tree with some occurrences of these words near together.
- grass and (tree or bush)
searches for objects indexed under grass, that are also indexed under tree or bush
- tree*
searches for objects indexed under any term starting with tree. We assume here, that the catalog uses Zope's globbing vocabulary. This vocabulary supports the wildcards * and ?. They match any character sequence or any character, respectively.
The catalog maintains for each cataloged object a collection of meta data, data about the object. It consists of data_record_id_ and the attributes or parameterless methods defined via the Meta Data Table tab. These attributes/methods are evaluated during catalog time, similar to the determination of an object's value for indexing, and stored inside the catalog independent from the object. Zope's search interface wizard uses these meta data to construct the report columns. I view this feature very critical as the so called meta data are actually not additional meta data but can be directly obtained from the object. Storing it with the catalog increases memory consumption and cataloging time; it introduces redundancy, which usually is not a good idea. I define a field only, if either of the following conditions is met: it is very small, such as id, it helps me to detect inconsistencies between the catalog and the object. This is true for bobobase_modification_time, the time, the object was last changed in ZODB., it is a computation intensive method, such as e.g. an intelligent summarization.
The catalog associates internally a unique number with each object, data_record_id_. It is part of the object's meta data table and available for each retrieved object. During cataloging, the catalog also stores the path to the object in order to find it again later during retrieval. The catalog provides two methods, that return either the path or the object itself, given a data record id: getpath and getobject. From Zope 2.3 on, the result of a catalog search behaves like a sequence of brain objects. Each such object describes one hit. Its attributes are the meta data values associated with the object. Furthermore, it provides methods getPath and getObject to access the corresponding path and object, respectively. With these new methods, you will probably no longer use the unique numbers.
Cataloging is only loosely coupled to the fate of an object. If the object is changed after it was cataloged, the cataloged information may no longer be accurate, if the object is deleted, the cataloged information about the object is still there. To fix such discrepancies, the catalog must be resynchronized. This can be done either globally, through the method manage_catalogReindex or for a single object with catalog_object or uncatalog_object (for deletion). There is a mixin class, CatalogAware, that helps (a bit) with the synchronization. CatalogAware objects handle creation and deletion automatically and provide a method index_object to be called explicitly after an object is modified. index_object is easier to call then the catalog's catalog_object. Of course, the object must find the catalog to be updated. It uses a catalog name, which initially is Catalog but can be changed.
How get objects cataloged? When they are CatalogAware, they will catalog themselves automatically when they come into existence. They can be cataloged explicitly with the ZCatalog method catalog_object. Alternatively, the catalog provides the method manage_catalogFoundItems for mass cataloging. Starting from the container containing the catalog, it searches all objects that meet given search criteria and catalogs them. If necessary, single objects can later be removed manually. These functions are available from Zope's management interface, too.
ZCatalog is an essential but unfortunately rather shaky Zope component. If something behaves strangely, then you have hit a catalog bug with some probability.
ZCatalog inherits from Folder. This implies, it is an ObjectManager. Usually, you will place DTML methods into the catalog that present search results. This implies that they have direct access to the catalog's methods. You may also place the objects to be cataloged there. In this case, they can directly use the catalogs methods for cataloging control.
ZCatalog's constructor is manage_addZCatalog.
ZCatalog's text indexes make use of Vocabularys. A vocabulary is a word expert. It knows how to split text into a sequence of words and then maps known words onto integers. A text index does not index the object under a word but really under an integer provided by a vocabulary for the word. The current Zope knows two types of vocabularies. A standard one and a globbing one. A globbing vocabulary recognizes the wildcards * and ? that match any word fragment or any single character, respectively. The globbing vocabulary expands such search terms into the sequence of words matching the term it knows about. The standard vocabulary does not recognize wildcards.
Zope 2.4 extensions
Zope 2.4 provides a set of new ZCatalog features and extensions. The index interface has been cleaned up and documented as PluggableIndexInterface. It is now much easier to implement custom index types and add them to a ZCatalog. Just create a class implementing the PluggableIndexInterface and register it with Zope.
ZCatalog provides now a builtin fourth index type, the path index. As the name suggests, a path index supports queries for objects with a given subpath in their path. Usually, the path must start with the given subpath, but the starting point can be controlled with a level search option. It is an integer that specifies at what path component matching against the query subpath should start. Its default is 0, starting at the root. A negative level searches objects with the given subpath somewhere in their path. The object's value for a path index is the object's physical path. It is split either with the object specific splitPath method or at / into a sequence of path components. The object is indexed under each pair path component, component index in sequence.
Zope 2.4 also provides more flexibility with respect to search specifications. Formerly, a search was specified by a flat dictionary mapping index names to subqueries for this index. Search options for index were specified by an entry index_usage. This form is still supported but deprecated. The new search specification is a mapping from index names to subquery specifications for the index. Such a subquery specification is either a dictionary or an object. The keys or attributes, respectively, specify the subquery. The main part is query, the search expression as described above; the remaining keys/attributes are search options, such as range (for range queries), operator (or or and to select the combining operator in case the search expression is a list, or the default operator for text indexes) or level (for path indexes). Other indexes can support further options.
Queries are often specified via forms. While it is difficult to create a nested dictionary structure from a form, the mapping to subquery specification objects can easily be created by means of the :record form variable name suffix.
1.13. Database integration
Zope supports database integration through two types of object classes: database adapters and Z SQL Methods.
A database adapter is an abstraction for a database connection. Usually, there is an adapter class for each supported database system, which includes Oracle, Sybase, Informix, MySQL, PostGres, SAP-DB. Furthermore, there are ODBC adapters that support the integration of any ODBC capable database (under Windows). The adapter provides a uniform interface towards the other Zope components and hides the specifics of the respective database system. Especially, the adapter is responsible to provide the necessary methods to play together with Zope's transaction system, to open and close the connection and to execute SQL statements against the database. Usually, the adapters also support data model browsing and the direct execution of queries from the management interface. A concrete adapter instance represents a single connection to a specific database. When you need to connect to a database, you would install an adapter product for the respective database type. After that you can instantiate adapter instances anywhere in your site. All objects below the folder with such an instance can easily use that instance.
A Z SQL Method is used to execute SQL commands against a database. Both queries as well as other, e.g. data manipulation, commands are supported. The configuration of a Z SQL Method consists of a reference to a database adapter instance, a set of arguments and a (DTML) template. While templates usually are used to generate HTML pages, the template of an Z SQL Method is used to generate a sequence of SQL statements when the SQL Method is called. These statements are then executed over the database connection identified by the adapter reference. If the SQL sequence contains a query[15], then the query result is converted into a Results object and returned as result of the call. A Results object behaves like a sequence of Record objects. Especially, it can be easily iterated over, subscription allows access to individual members, the len function can be used to determine the number of records and an empty result sequence is a Python false value. Each Record describes one row of the query result. It is an object with an attribute for each result column. The attribute contains the value for the respective column in the represented row.
The template can use all DTML commands and some additional commands specially designed to facilitate the construction of SQL commands. The names of these additional commands all start with sql. See the DTML reference in Zope's online help, for details. If several SQL commands are generated, they are separated by <dtml-var sql_delimiter>. The template can access the Z SQL Method's arguments and names acquired from the Z SQL Method's context.
A Z SQL Method's arguments are specified as a whitespace separated list of argument specifications. In the simplest case, an argument specification consists of an argument name. However, it may also specify a default value, given after an =. If the default value is empty or contains whitespace, if must be enclosed in double quotes. In principle, it should be possible to specify an argument type, but this is currently broken. When the method is called, arguments can be specified in either of the following mutually exclusive ways:
| by providing corresponding keyword arguments, |
| from the request object. |
For efficiency reasons, the result of Z SQL Methods can be cached. As always, caching can significantly increase performance. But there are drawbacks, too: as a result of caching, stale information can be delivered. Therefore, caching is disabled by default. When you enable it, you specify how many results may be cached (thus limiting the amount of resources) and how long a result might be cached (thus limiting the life span of stale information). The cache is maintained on a per thread basis. Therefore, it is difficult to flush the cache explicitly and the standard Z SQL Methods do not provide a method for this. If you want to use long term caching, your database is only modified by Zope and you do not want to accept stale information, you can use my Cache Controlled Z SQL Methods. It maintains its cache thread-independent and provides a method to explicitly flush the cache. You would use this method, when your Zope application modified the database and potentially had invalidated the cache content.
As described above, the result of a query is usually a sequence of Record objects that present the corresponding row as a simple object whose attributes correspond the the result columns. However, you can wrap these records into a class of your own, called a brain. This class can give the records interesting behavior. Although essentially a stupid sequence of values in the database, this feature may make a row into a full blown object[16] .
If a Z SQL Method has a single argument, then the Z SQL Method can be called directly through the Web by appending the value for the argument as URL segment after the URL to the SQL method. This feature, direct traversal, is usually combined with a brain that provides behavior, e.g. displays the result.
1.14. ZClass
We know already all Zope objects necessary to build simple Web applications. For example, it would not be difficult to implement our guest book with a folder as a container for out guest book entries, a catalog to search for them, a DTML document for each guest book entry and DTML methods to implement the search mask and present the search results. Things become more difficult, when such small applications should be instantiated more than once or tightly integrated with other applications on the same Web site. This is the case, for example with our friends and artists. To handle such requirements, Zope provides ZClasses.
What is a ZClass? Easily spoken, it is a blueprint for a Web application or part thereof. We will e.g. define a friend ZClass. It will implement all friend related operations and provide the basic structure for the friend related attributes: annotation management, profile management, registration information, home page design, to just list a few. Technically, a ZClass is an object class which can be instantiated to create objects, instances of the class, which are also called ZInstances. We will instantiate the friend ZClass, whenever we need a new friend object. Each friend, once instantiated, can use all facilities defined by the class. If we later decide to change or enhance the facilities, we need only to modify the ZClass and not the various ZInstances. All instances will immediately observe and use the changed infrastructure.
A ZClass has associated methods and property sheets. The methods are defined through arbitrary objects. Usually they will be DTML methods or Python scripts. However, nothing prevents you, to use images, files or even folders[17]. All methods are exposed as ZInstance attributes and therefore can be directly accessed through their id. Each property sheet is a named PropertyManager[18] and manages a collection of (usually related) properties. The properties from all sheets are exposed as attributes of the ZInstance, i.e. they can be directly accessed through their id. All property sheets are exposed as attributes of the attribute propertysheets. This is necessary for property modification.
A ZClass can use inheritance, even multiple inheritance, for its definition. As mentioned earlier, this allows class composition out of pre-packaged components, each implementing a special facility. Available as base classes are other ZClasses and product classes that have been registered as ZClass bases[19].
As you see a ZClass is very similar to a class. The major difference is that ZClasses can be build through the Web. Its methods are arbitrary other Zope site building objects.
Currently (Zope 2.3), a ZClass can only be created in a product (or another ZClass). Products are managed via Zope's management interface Control Panel->Product Management. In a product, a ZClass is created via the management interface's add list. Once defined, top level ZClasses (i.e. ZClasses not defined inside another ZClass) can be instantiated in all object managers, provided the instantiator has the necessary permissions. This implies, that not the ZClass but the ZInstance is a site building object. The ZClass is only the blueprint for application specific site building objects.
To learn more about ZClasses, the corresponding chapter in the Official Zope Book [Zope] is recommended reading.
2. Web publishing
In this section, we look more closely into the basic concepts behind Web publishing. The first subsections give basic background information. This information is not essential to follow the book but it may help you to get the big picture and understand how the various parts fit together. Such an understanding can be quite vital in abnormal situations, where something does not work as it should be. The last sections are essential for the remaining parts of the book.
2.1. HTTP
Today, almost all Web publishing uses the HTTP (HyperText Transfer Protocol) [RFC 2616] or its "secured" version HTTPS [RFC 2818] which it HTTP over TLS (Transport Layer Security) [RFC 2246] or its predecessor SSL (Secure Socket Layer).
HTTP is a very simple protocol: a client sends a request to a server; the server processes the request and replies with a response. Requests and responses are send as messages over a TCP connection. The message format is essentially MIME (Multi purpose Internet Mail Extension) [RFC 2045-2049], a format used, too, to transfer multi media mail messages across the Internet. A MIME message consists of a set of headers and a body, also known as message entity. The body is optional for HTTP messages. The standards speaks of it as the HTTP entity. For HTTP, a request or response line, respectively, is prepended to the message.
A request line consists of the request method, the resource locator and the protocol version. A resource can be anything: a HTML page, an image, a file, a database, a service, an application. It is identified by the resource locator, a path to easily locate the resource in a hierarchical structure such as e.g. a file system or Zope's folder structure. HTTP uses the URL syntax for the resource locator. It is up to the receiving HTTP server to determine what resource the resource locator does really identify.
HTTP knows a set of request methods. The most essential are GET, POST, PUT, HEAD. GET requests all information about the resource to be transfered in the response. HTML's link traversal and image references are mapped to GET requests. HTML form submission may use a GET request. Additional request headers can make the request into a conditional request or a request to transfer part of the information. Both request modifications are intended to reduce communication traffic. A GET request should not have side effects and should be idempotent. Idempotence means, that a repetition of the same request results in the same response. HTTP clients often use this fact and assume that GET requests can be cached. They save the response to such a request and take the response from their cache when a later GET request targets the same resource. For a Zope Web site, many requests do have side effects. This is especially true, if a session management device is employed. In such cases, it may be necessary to fight with the caching behavior.
A POST request sends information to a resource that this should integrate subordinate to itself. POST requests usually have side effects. You would use a POST request for example to create a new database record, update the properties of a Zope object or post a news item to a discussion board. HTML form submission often uses POST requests.
A PUT request sends information that the server should use to create a resource located by the request resource locator. If there is already such a resource, it may be overwritten. PUT requests are not used from HTML. HTML editing tools use PUT requests to publish an object on a Web site.
A HEAD request is similar to a GET request. It is expected to have no side effects and be idempotent. It should return the same headers as a GET targeted to the same resource but should not transfer the message body. HEAD is not used from HTML. It is, however, used by link validation and indexing tools, to efficiently check the existence, the type, size and other meta information for a resource. It is difficult for Zope to meet the requirements for this request type. Most of its objects are templates that need to be rendered in order to obtain full header information. Rendering, however, can have unwanted side effects. Zope, therefore, returns only approximate, sometimes even wrong information in response to HEAD requests.
A resource may be finer grained then the location of an object in a hierarchical structure. Resource locators for GET and HEAD requests may have a trailing query string that provides additional parameters. The query string is started with a ? which is followed by a sequence of & separated parameter definitions of the form name=value. For POST and PUT requests, parameters may be present in the request body. Their packaging there is indicated by the request's Content-Type header (by e.g. application/x-www-form-urlencoded or multipart/form-data). In Zope, ZPublisher takes care of the parameters, independent whether they are provided as part of the resource locator or in the request body, and makes them accessible in a standard way.
A response begins with a response line. This consists of the protocol version, the numerical status code and the textual status phrase. The status code, a three digit decimal number, tells the client, what happened with the request. The code is divided into classes based on the first digit.
The codes 1xx represent informational responses.
The codes 2xx tell the client that the request has been successfully executed. Usually, the remaining response contains an entity as the primary request result. The usual return code is 200. Other codes indicate, that special information is available in response headers or that the browser should behave in a special way.
The 3xx class calls for redirections. The request is not completed but requires special actions from the user or his user agent. For security reasons, HTTP requires that redirections are only performed automatically for GET and HEAD requests. All other request types require user confirmation. The redirect method of Zope's RESPONSE object uses a 302 status code with the location header set to the new URL. For some objects, especially files and images, Zope responds with a 304 response to GET requests made conditional with an If-Modified-Since header, if the object has not been modified since the given date. In fact, this response is not a redirection. It completes the response without sending the entity data. Conditional requests of this type are usually send for objects in a client's cache when the cache validity should be checked. A 304 response indicates in this case, that the cache entry is still valid and the request can be served from the cache. If the object has been changed since the given date, Zope responds with a 200 response that contains the new information. By default, Zope does not employ this mechanism for template objects as their modification date is not decisive to determine whether or not the generated page remains the same. As it is too difficult to get this right in the general case, Zope always processes such requests as unconditional. However, applications with special efficiency concerns may explicitly generate a 304 response if they can guarantee validity. As of version 2.3, Zope provides an integrated cache manager that can help you to control caches both inside and outside of Zope.
The 4xx status codes indicate a client error. Usually, the response contains an entity that explains the problem and what can be done about it. The most essential codes are
- 400
The request is malformed or otherwise not understood.
- 401 (Unauthorized)
The resource is protected. Authentication may allow access to the resource.
- 404
The requested resource is not found. HTTP allows the server to cheat. The code is a catch all for all types of client errors, the server does not want to give a more detailed description for.
5xx status codes indicate a server error. Zope uses code 500 (internal server error), when some application code tries to set an invalid status code or when it raises an exception that Zope is unable to map to another status code (such as redirect or unauthorized). When Zope is connected to through a proxy, a client may observe other status codes from this class. It usually indicates that either Zope or another proxy on the way to Zope died or a connection broke down.
HTTP is a stateless protocol. This means that a request must contain all information necessary to process it. The server is not expected to have saved state information from previous requests that may be necessary to process this one. This HTTP property makes it quite hard to build more complex Web applications. Of course, users expect from most applications that they are aware of their preferences and remember essential facts from previous interactions. A whole mess of kludges have been defined and implemented to work around this limitation: authentication headers, hidden form variables, cookies, session products. We will learn about these concepts later in this book. I expect future HTTP versions to remove this limitation.
2.2. URL
The URL (Universal Resource Locator) is one of the most essential Web publishing concepts. As the name says, it is used to locate a resource. As we explained in the last section, a resource is used in a very wide sense: it can be almost anything, a person, an object, a service, an application etc. Almost the only requirement is that it can be identified with an identifier, an URI (Universal Resource Identifier). There are different kinds of identifiers. Some kinds contain a description how to locate the resource. These form the subclass of the resource locators, the others are the resource names, URN's. The URI syntaxes for the various kinds have many commonalities. Therefore, the common aspects can be described in a single URI syntax standard [RFC 2396]. Each URI kind is identified by a scheme. Although the scheme determines the precise syntax, URIs, especially URLs, usually consist of up to 4 components: the scheme, an authority, a path and a query. The scheme is always present. It determines which of the other components may or must be present. This means, the generic syntax looks like:
scheme: [authority] [path] [?query]
For resource locators, the scheme usually identifies a protocol which can be used to access the resource. The remaining URL parts provide the parameters necessary for this access. The most prominent protocols in the Web publishing domain are http and its secured version https, as well as mailto and ftp. The mailto protocol accesses the resource, usually a mailbox or mail group, by sending an email to it. The URLs use only the authority part which usually has the format user@host.
The other listed protocols belong to the family of hierarchical URI schemes. Their commonality is the use of the path component, a sequence of (path) segments separated by /. Paths can be used to navigate in a (typically) hierarchical structure: to locate path/segment, segment is used as a local selector in the context of the resource located by path. You know this type of navigation from your file system and indeed the resources are often folders and files in a standard file systems and the URL path component directly mapped to the file hierarchy.
A segment has the form of an id optionally followed by a sequence of parameters, each one preceeded with a ;. These parameters are a recent extension to the URI syntax. Formerly, the path component as a whole could have a single parameter section as suffix. Zope's URI parsing algorithm[20] still follows this older specification and terminates the path as soon as it sees the first ;. It does not interprete parameters or makes them accessible to the application.
For hierarchical URI schemes, the authority component typically has the form
The host identifies the name or Internet address of a host where a service at port should resolve the URI into a resource. If port is not specified, a protocol specific default is used. This is 80 for HTTP, 443 for HTTPS and 21 for FTP. If present, userinfo identifies the user for whom the resolution and maybe an associated request should be performed. It has the form username[:password].//[userinfo@]host[:port]
The query component is a string of additional information, interpreted by the resource. For HTTP, it usually is a sequence of name=value components, separated by &. Zope interprets them as argument definitions and makes them available directly via their name.
What is usually used in documents are not URIs but rather a more general concept, an URI reference. An URI reference is essentially an URI, but two aspects make it more general than an URI. An URI reference may have an attached fragment identifier, introduced with #. It identifies a fragment, a part of the resource identified by the URI. And the URI reference may be relative, i.e. it may only specify part of the complete URI with the missing parts given by a base URI. The fragment part is only interpreted by user agents, usually to position the view onto the displayed resource. It is never sent in a request. Likewise, relative URI references are resolved with respect to their base URI to form an absolute URI and only these absolute URIs are sent in a request. A relative URI reference does not follow the above mentioned URI syntax, it is rather a suffix thereof, especially it does not have the scheme component. The rules to resolve a relative URI reference with respect to its base into an effective absolute URI are as follows:
If the relative reference is empty or consists just of a fragment, then it references the current resource.
If the relative reference starts with two slash characters, then the effective reference gets its scheme from the base URI and everything else from the relative reference.
Otherwise, if the relative reference starts with a single slash, then the effective reference gets its scheme and authority from the base URI and everything else from the relative reference.
Otherwise, the effective reference gets scheme and authority from the base URI, query and fragment from the relative reference. To construct its path, the path of the base URI and the relative reference are merged as follows. All characters in the base path following the last / are discarded, then the path of the relative reference is appended. All segments consisting of . are discarded and then, from left to right, all segments consisting of .. are discarded together with their preceeding segment.
As we speak about Web publishing, most resource references embedded in pages will be URL references: references to images, other pages, mail addresses. If the resources are local, you should usually try to reference them by relative references with respect to the current page. Relative references have the advantage that you can often rename or move a substructure without the need to change all your references. Using relative URLs with respect to the current page works because the default base URI for resolution of relative URIs is the URI of the current document. HTML provides the base tag, a header component, to explicitly specify the base URI. Under some circumstances, the URL used by the HTTP request is not the canonical URL of an object, as would be necessary for correct resolution of relative URLs. Zope knows about many of these circumstances and generates automatically a corresponding base tag. For cases where this is not possible, Zope provides a method that allows the application to set the base.
As we have seen, there are many characters that have special meaning for URI parsing. If they need to be used literally, i.e. as part of one of the URI components rather than as component separator, then they must be encoded. Furthermore, some characters have platform dependent representations. This induces problems for cross platform applications such as Web publishing. There are other problems with some control characters. The URI standard therefore severely restricts the set of characters that can occur unencoded as part of the various URI components. The only characters that can be used unrestrictedly are the ASCII letters (upper and lower case), the ASCII digits and the characters from the set -_.!~*'(). Depending on the URI component, other characters may be allowed, too. For example, the characters :@&=+$, are additionally allowed in path segments. However, you should think twice, whether you really want to use such facts. Any character not allowed in a context must be encoded. The encoding consists of % followed by the two hex digits representing the character's code in the ISO-8859-1 encoding, also known as Latin-1. This is a superset of the ASCII character set. You do not need to worry about the coding details: Zope provides a function url_quote that encodes strings correctly to be used as URI components. You must be aware, however, that encoding is necessary at some places and use url_quote at these places. Zope decodes URLs automatically. Thus, there is usually no need to worry about this aspect.
2.3. HTML FORMs
Currently, most Web published pages use HTML, the HyperText Markup Language. There are tools that allow you to create and modify HTML pages WYSIWYG or at least guided by menus. These are so call HTML editors. Examples are DreamWeaver from Macromedia, Microsoft's FrontPage or Netscape's Composer. However, these tools are designed to build static, stand alone pages. They are of lesser practical use to work on page templates with their additional tags not understood by the tool and their usually non HTML-conformant macro structure[21]. This implies that for page template design you need a basic understanding of HTML and a tool that lets you use unknown tags and build non-standard pages. Such a tool would usually not support full WYSIWYG editing but may provide menu guidance. Personally, I use XEmacs' HTML mode. But there are many other simple HTML editors for this task, such as HTMLKit.
Although a basic HTML understanding is necessary to build dynamic Web sites with Zope, it is beyond this book's scope to provide a thorough HTML introduction. I, personally, look into the HTML4.0 specification when I need information about HTML. In my view, it is a very good specification which provides introductions, well structured overviews and detailed information combined with good navigation support such as element and attribute indexes. In this book, we will only look at HTML forms, as they are especially important for dynamic Web sites.
An HTML form is the major device that allows users to provide input for Web applications. It is implemented by the HTML form tag. The form tag contains special form controls beside normal text and HTML markup. Controls have a name, an initial value and a current value. The user interacts with the form by changing the current value of its controls, either directly or through script invocations. He may then submit the form. Form submission results in a request being send to an agent, e.g. an email server or an HTTP server. Depending on the context of submission, some controls are being considered successful. For each successful control, the request contains an association control_name=current_value. The order is the same as the controls appear in the document.
Controls are implemented as HTML tags. Their name is given by a name attribute. Their initial value is usually given by a value attribute, for some controls by their content (textarea; option if no value attribute is present). The current value is initially set to the initial value and can later be changed either by the user or a script. Values are strings.
There are controls for (single line) text input, image, submit, check, radio and reset buttons and file input, all implemented by the input tag. Menus are implemented by select, which is a container for options and is available both as a single and a multiple selection. Multi line text input is implemented by textarea. HTML 4 provides additional button and object controls. As a special case, there are hidden controls, also implemented by input. They are used not for user interaction but to transfer information between the page generation process and the request processing after form submission. Such a transfer may be necessary to work around HTTP's lack of state which requires that each request is self describing. Cookies provide an alternative to the use of hidden controls.
Whether a control is successful during form submission is usually determined by its type and its current value. Text input and hidden controls are always successful. Check and radio button controls are only successful, if checked. For selections, each selected option defines a successful control associated with the selection's name. Thus, there may be one, several or none successful controls for a single (multiple) menu control in the submitted form data. A submit or image button is only successful, if it was used to submit the form[22].
It should be noted, that unsuccessful checkbox controls can make problems during form processing. Similar problems result from multiple selections when no option has been selected. In all these cases, the submitted form data does not contain a definition for the associated control name. The application must take care, to interpret this lack of a value correctly. Zope provides various facilities to handle these cases.
The form tag has one required attribute, action. Its value is an URI reference and specifies the resource that should process the form data when it is submitted. Usually, it is either a mailto or http/https URI. In the first case, the form data is send by email to the given URI, in the second case, an HTTP request is sent. form has several optional attributes, the most essential being method and enctype. method's value is either GET (the default) or POST. When the GET method is used, then the form data is provided as query string in the request locator of an HTTP GET request. As we have noted, the allowed characters inside an URI are severely restricted. Characters not allowed must be encoded, which results in a three byte code for each single byte character. Therefore, this method is inefficient for non-ASCII strings or binary data. You should use POST when your form transmits large non-ASCII strings or even files. If the action specifies a HTTP URI, then an HTTP POST request is used to transfer the form data. Here, the form data is contained not in the resource locator but in the request body. The enctype (encoding type) determines in this case the content type of the request body (and thereby the encoding of the form data). The default enctype value is application/x-www-form-urlencoded, which is the same encoding used for URL encoding and therefore, is inefficient in the same cases as the GET method. Do not use it when your form contains files. Use in these cases multipart/form-data. This uses a multipart MIME message to encode the form data. It can contain binary parts and therefore transfer binary data efficiently. If the form data is sent as email to a human, then text/plain may be appropriate as value for enctype. With this encoding, each successful control results usually in a line of the form name=value without an encoding of characters in name or value. This is adequate for humans. If the email recipient is a program one of the other encoding may be more appropriate as they present no parsing ambiguity and there are standard tools for parsing. If a form is submitted to Zope, any of the request methods and encoding types (exception text/plain) are handled transparently and the form data made accessible in a convenient way.
Example 3.3. Example HTML form
<FORM action="http://somesite.com/prog/adduser" method="post">
<P>
<LABEL for="firstname">First name: </LABEL>
<INPUT type="text" id="firstname"><BR>
<LABEL for="lastname">Last name: </LABEL>
<INPUT type="text" id="lastname"><BR>
<LABEL for="email">email: </LABEL>
<INPUT type="text" id="email"><BR>
<INPUT type="radio" name="sex" value="Male"> Male<BR>
<INPUT type="radio" name="sex" value="Female"> Female<BR>
Interests:
<SELECT name="interests" multiple>
<OPTION value="1">Sports</OPTION>
<OPTION value="2">Politics</OPTION>
<OPTION value="3">Arts</OPTION>
<OPTION value="4">Economics</OPTION>
<OPTION value="5">Family</OPTION>
</SELECT><BR>
Origin continent:
<SELECT name="origin">
<OPTION>North America</OPTION>
<OPTION>South America</OPTION>
<OPTION>Asia</OPTION>
<OPTION>Australia</OPTION>
<OPTION>Europe</OPTION>
</SELECT><BR>
Interested in further information:
<INPUT name="info" type="checkbox" checked>
</P>
<h4>Remarks:</h4>
<P><TEXTAREA name="remarks" cols=60 rows=10></TEXTAREA></P>
<P>
<INPUT type="submit" value="Send"> <INPUT type="reset">
<INPUT type="hidden" name="sessionId" value="2417369">
</P>
</FORM>This example (partly stolen from the HTML 4.0 specification) shows a simple form containing most available controls.
The Forms chapter of the HTML specification contains more detailed information about forms and form processing. It is very recommended reading.
2.4. Authentication
Unlike a static Web site where visitors usually can only retrieve data, a dynamic Web site built with Zope allows in principle all types of site extensions and modifications performed through the Web. It is clear that an administrator wants to control who is entitled to perform such operations. Authentication, the determination of the identity of a requesting agent, is vital for a dynamic Web site.
HTTP provides for an elementary authentication scheme. It is rightfully termed basic authentication [RFC 2617]. HTTP requests can contain an Authorization header. The authorization header identifies the authentication scheme, an authentication token and optionally parameters necessary to interpret the authentication token. For the basic authentication, the scheme is Basic, the token is the base64 encoding of username:password and parameters are not used. When an HTTP server receives a request requiring authorization, it will examine the authorization header. If it is missing or it does not provide for the required authorization, the server will return an Unauthorized response to the client. The response contains a WWW-Authenticate header with one or more challenges. Each challenge consists of an authentication scheme and a sequence of parameter definitions. For basic authentication, a single parameter is defined: realm. Its value is a quoted string. The server URL and the realm value define the protection space of the required authentication. An interactive user agent (a browser) will usually pop up a login dialog for the server and realm when it receives such a challenge, unless login information for the given protection space is already available. The login dialog will ask the user for its username and password with respect to the protection space and will remember this information at least for the session duration. It will then construct an Authorization header from the login information and include it in all requests sent to this server until it receives a new Unauthorized response from this server, maybe for a different realm.
Basic authentication has two weak points. The first is security: username and password are essentially sent in clear text (They are sent base64 encoded. However, it is trivial to reconstruct the original information from the encoding) with every request. Anyone that intercepts such a request can extract the username and password and use it to obtain a false identity. The second is comfort: the lifetime of the login information is controlled by the browser. It usually maintains it during the current session (i.e. the lifetime of the browser process)[23]. In this case, the user has to reauthenticate each time he restarted its browser.
Recently, a more secure authentication scheme has been defined for HTTP: digest authentication. However, it is not widely implemented. Especially, Zope does not yet support it (but many browsers do not, too).
The authentication scheme used by a Zope Web site is not hard-wired into Zope. Instead, a component, the so called UserFolder decides about all authentication aspects. The standard UserFolder which comes as part of Zope supports only basic HTTP authentication. There are, however, products that use cookie authentication.
With cookie authentication, the authentication token is not sent in an Authentication header but in a cookie. The token usually is not the clear text username and password but some meaningless hash value that is only identified with the user inside the server. Therefore, this scheme appears to be more secure. However, security is increased only marginally. Any request will carry the cookie. An interceptor of such a request can fetch the cookie and use it himself to steal the associated identity with respect to the corresponding server. It is a bit more safe, as it is more difficult to get at the clear text login information. This is essential if the same password is used for other purposes or passwords for different purposes are constructed according to some scheme. However, the cookie authentication provides much more control for the application. It can specify the cookies lifetime. This can either be used to limit the validity period for the authentication token and thereby for a potentially stolen identity. It can also be used to save the cookie for a long time and eliminate the need for logins (almost) altogether. This can be seen as a big advantage by casual users that might otherwise tend to forget their passwords.
Some people (I am one of them) do not like cookies because of privacy concerns. Cookies are often used by Web sites to identify their visitors across visits, collect long term information about their visits and visit patterns and use this information in various ways: to improve their Web site (good), to analyze their visitors interests and use it for personalized marketing (I do not like that), maybe even sell this information (I hate that). Therefore, I look regularly in my cookie file (where the browser maintains long living cookies). When I detect cookies with a lifetime of more than a month or so, I get very suspicious about the site's intentions. I delete such cookies and may disable cookies altogether when visiting such a site.
2.6. ZPublisher
ZPublisher is the component of the Zope framework that is responsible for the following tasks:
build special objects REQUEST and RESPONSE,
fetch arguments, whether in the query string of the request locator (if the request method is GET or HEAD) or the request body (for other request methods), and decode them, if necessary,
convert and/or package request arguments based on type suffixes of the argument names,
resolve the path in the request locator into an object. This is called traversal,
initiate user authentication,
call the object or method located during traversal with the parameters required or available,
handle any exceptions raised during this process.
We will now look into these tasks in more detail.
2.6.1. Build special objects REQUEST and RESPONSE
REQUEST will contain the complete details about the request. RESPONSE will later generate the HTTP response. Its methods can be used by application specific parts to influence this generation. Both objects will be described in detail in the next section.
2.6.2. Fetch arguments
The request can contain arguments to further specify what should be done or provide data for the action. For GET and HEAD requests, arguments are contained in the query string, for other request methods in the request body. Parameters are often encoded with different encoding schemes and can be serialized in different ways. ZPublisher fetches and decodes them as necessary.
2.6.3. Convert and package arguments
With the exception of files, all HTTP parameter values are strings. Often, however, functions need different data types as arguments: numbers, dates, structures. Of course, the functions could implement conversion from strings to the required data types themselves. However, it is nice to have this centralized. ZPublisher can provide the required conversions. It looks at type suffixes in the argument names and interprets them as requests to either convert the argument value to the given type or to package it with other values into a larger type. For example x:int=1 tells ZPublisher to convert the string value 1 into the integer 1 and associate it with the argument x. A single name can carry several type suffixes, for example x:int:list=1. The result is that the parameter x is defined with a list as value. The list has a single element, the integer 1.
ZPublisher recognizes different kinds of suffixes: converters, packagers, actions, controllers. Usually, names should have at most one suffix from each kind. Thus, there should not be two converter suffixes, but a converter and a packager is okay[24]. The order in which suffixes from different kinds appear is not significant.
2.6.3.1. Converters
Converters convert the value into a given type and raise an exception, if this is impossible. All converters accept file values, too. Such files are read to obtain a string that is then converted. Zope supports the following converters:
- float, int, long, string
converts into the indicated Python types
- date
converts into a DateTime object. The value may be any string accepted by the DateTime constructor. It includes date strings in any form unambiguously recognized in the US and may have an optional time part. Look into the API reference in Zope's help system for details.
- tokens
convert into a list of strings by splitting the value at whitespace
- text
normalizes line endings. This may be useful for textarea values, as MS Windows and Unix have different line ending conventions.
- lines
converts into a list of strings by splitting at line boundaries
- required
converts into a string and raises an exception, if the string is empty
- boolean
converts into a boolean, mapping the empty value to false and any other value to true[25]
2.6.3.2. Packagers
Packagers pack several parameter definitions with the same or related names into larger structures to make them easier to access. Zope supports the following packagers:
- list
package all parameter values with the current parameter name into a list. In fact, this is the default, as soon as the request contains two or more definitions with the same name. Use the list packager, to get a list, even if the request contains only a single parameter definition for the given name. You will use this for form fields corresponding to multiple selections in order to handle the selection of a single or multiple items in a uniform way. Note, that the case "no items selected" must still be handled specially as in this case, the form control is unsuccessful and there is no parameter definition for it in the request.
- tuple
package all parameter values with the current parameter name into a Python tuple. Tuples are very similar to lists but are read only, which Python calls immutable.
- record
The current parameter name must have the form name.attribute The record packager collects such parameter definitions with the same name part into a record with the respective attributes and makes it available under name. If, for example, there are parameter definitions person.name:record=dieter person.email:record=dieter@handshake.de, then a record is build under the name person with attributes name and email and values dieter and dieter@handshake.de, respectively.
- records
like record but it constructs a list of records. It seems magically for me how it determines when it should start a new record.
2.6.3.3. Actions
Usually, ZPublisher calls the object selected during traversal to generate the HTTP response. If, however, the request contains an action, then this action determines the object to be called.
Actions can have too forms: name:action_suffix=value or action_suffix=value. In the first case, name designates the object to be called and value is ignored; in the second case, value designates the object. Usually, the first form is used in form buttons, while the second form is used when the form action is to be determined by a Javascript. In both cases, the object designation can be a sequence of path segments, separated by /. It is interpreted in the context of the object determined by traversal. Its effect is very similar to an extension of the request locator path by the object designator. The feature exists to make processing of forms with more than one button easier. Each button can directly specify the method implementing its operation.
There are two different types of actions: default and specific action. A default action can be overridden by a specific action. The default action uses the type suffix default_method (or its alias default_action) while the specific action uses method (or its alias action).
2.6.3.4. Controllers
Controllers control, how ZPublisher processes the given parameter definition. ZPublisher implements the following controllers:
- default
The definition defines a default value that should be used, when there is no other definition for the same parameter name. This feature is often used for checkboxes. Usually, an unchecked checkbox is not successful. It, therefore, will not contribute to the form data incorporated in the request making it difficult to reset the value corresponding to the checkbox. The default controller allows to provide the reset value for this case.
- ignore_empty
The definition is ignored, if its value is empty. This allows to make use of default parameter values of Python functions instead of this definition.
2.6.4. Traversal
During traversal, ZPublisher traverses the Web site guided by the path component in the request's resource locator. We saw that an URI's path is a sequence of path segments.
ZPublisher performs a sequence of traversal steps, usually one for each path segment. In each step, ZPublisher starts with an object, the current object, and has a sequence of path segments still to be traversed. It interprets its first segment as an accessor in the current object's context to get the next object. Usually, the next traversal step will use this object as current object and the segment sequence with the first segment removed. The process stops, when either all path segments have been processed or the current path segment does not access a new object[26]. The second case usually indicates an error[27]. ZPublisher starts the traversal with the root object and the complete request locator's path.
If there is an object index_html accessible in the context of the object located during a successful traversal, then ZPublisher will select this index_html; otherwise, it will select the located object. This behavior is similar to that of other Web servers. They will look for an index.html in a context located by the request locator path (usually a folder) and return that.
The remaining parts of this section are relevant only for product developers. Other readers may skip them.
ZPublisher provides two traversal hooks. As we said in the introduction, a hook is a step in a procedure where the application can take over control when the normal framework implementation does not fit its needs.
The first hook is called __before_publishing_traverse__. If defined, it is called at the start of a traversal step. It is defined when the step's current object has such an attribute. The attribute will be called with two arguments, the current object and the request object. Its return value is discarded, thus only its side effects are essential. Usually, it will modify the request object. The modification may be as simple as defining additional parameters or providing defaults. However, the request object also provides methods that change the path segments still to be traversed. Therefore, the hook can drastically change the traversal. This is used for example to implement virtual hosting or to facilitate internationalization. Products that use this hook are for example SiteAccess2 (for virtual hosting) and Localizer (a localization tool).
The second hook is called __bobo_traverse__. If defined, it customizes the "accessor" notion. As we have seen, during a traversal step, ZPublisher uses the first path segment as an accessor to find the next object in the current object's context. Its default behavior is to first check for an attribute of the given name, then for a (mapping) key, then fails. However, if the current object has an attribute __bobo_traverse__, then this function is called with the request object and the segment as parameters to determine the next object. It can even return a tuple of objects. In this case, the last element defines the next object while the preceeding objects define the path to this object replacing the current object. This hook is used, for example, to implement advanced features of ZSQL methods such as direct traversal.
During traversal, ZPublisher builds a sequence of objects visited during traversal to the final selected object. It makes the reverse list accessible as the request member PARENTS. PARENTS[0] is the object's parent, the object visited before this object; PARENTS[1] is the object's grand parent, and so on. The object itself is made available via the member PUBLISHED.
2.6.5. Initiate Authentication
Once ZPublisher has determined the object to be called during the traversal, it initiates authentication. It does not authenticate the user itself, but cooperates with other Zope objects, so called UserFolders to fulfill this task.
First, ZPublisher determines which roles can call the object. Then, ZPublisher goes back along the chain of nodes it had visited during traversal (but in reverse order). It checks each node, whether it contains a UserFolder instance and if it does, whether this user folder can authenticate a user with the required roles. If authentication is successful, ZPublisher places the resulting user object as AUTHENTICATED_USER into the REQUEST object. Otherwise, ZPublisher continues its search towards the site root. The highest UserFolder will return the Anonymous user, if it cannot authenticate the user and calling the object does not require special roles. If ZPublisher has reached the site root without being able to find a user folder that authenticated the user with sufficient privileges to call the object, it raises an Unauthorized exception. If not overridden by application specific code (e.g. special user folders), such an exception is turned into an "Unauthorized" HTTP response. Such an HTTP response causes the browser to pop up a login dialog.
2.6.6. Call object/method
Now, that traversal has determined the object to call and the necessary authorization is checked, ZPublisher can call the object.
ZPublisher looks into the object and determines what parameters are mandatory or optional for the call. It then looks into the REQUEST object and then the objects context, in this order, to find such parameters. It then calls the object with the parameters found, raising an exception if a mandatory parameter has not been found.
ZPublisher calls the object inside a transaction. This makes is possible to undo most types of side effects of the call in case it should fail[28]. If the call raises an exception, the transaction is aborted. When the call returns without exception, the transaction is committed and other requests can see potential effects by this call.
2.6.7. Handle errors
ZPublisher handles all errors that occur during its proper operation or exceptions raised during the object call. It turns them into appropriate HTTP responses.
2.7. Special Zope objects
ZPublisher defines two objects REQUEST and RESPONSE. They facilitate the interaction between the ZPublisher framework and the (usually) application specific published object.
It is essential to note, that these objects are not persistent. As soon as the current request is completed, they disappear. Many Zope beginners are not aware of this.
2.7.1. REQUEST
REQUEST contains the complete information about the current request. The most relevant information is available redundantly, in both the original unprocessed form and in a preprocessed form for easy access.
REQUEST exposes its data as a mapping object[29]. We speak of the request data as the request items or the request variables.
DTML allows you to easily analyze what a request really contains. The DTML template fragment
<dtml-var REQUEST>inserts the current request's data in a clearly formatted HTML structure. This is very useful, in case your form submissions result in difficult to understand behavior.
2.7.1.1. Request item categories
You can use REQUEST[key] to access the value associated with key. However, as an HTTP request is complex and contains names in several categories that might conflict with one another, it is sometimes helpful to know, that REQUEST has a finer grained structure that allows to access the names in the different categories in a controlled way.
2.7.1.1.1. Explicitly defined request items
The REQUEST method set allows to explicitly define request items. They are collected in the member other, a mapping object. Such definitions are often used to work around a weakness of document templates: they do not support variables that can change their value in the cause of template rendering. Explicitly defined request items are used as a substitute for such variables.
For efficiency reasons, this mapping is used, too, to provide access to form data and cookies. If a name is looked up in REQUEST, then effectively it is looked up in other, and if not found there, it is checked whether it is a Zope defined name or HTTP header. As cookies and form data should be accessible, too, via REQUEST lookup, they are merged into other during initialization. For this merge, form data has higher priority than cookie values.
2.7.1.1.2. Form data
The member form is a mapping with all argument information determined by ZPublisher. Usually, this argument information comes from form submission. This gives this member its name. However, arguments can also come from an explicit query string in an URI reference.
2.7.1.1.3. Cookies
The user agent sends all cookies that may be relevant for the request in the HTTP header COOKIE. For ease of use, ZPublisher parses this header into the various cookies and makes them available in the member cookies, another mapping.
The COOKIE header may well contain different cookies with the same name. In this case, cookies will map the name to the first value found for that name. According to the cookie specification, this is the most specific cookie value with the given name available for the request locator.
2.7.1.1.4. Zope defined request items
Zope defines the following items to facilitate special tasks:
- REQUEST
the request object itself. This is a convenience definition for document templates. They have direct access to the names defined by the request object as a mapping. However, is some cases, they need to access the object itself, e.g. to access its members or methods. They can do this via REQUEST.
- RESPONSE
the response object
- PUBLISHED
the published object. This is the object determined during traversal which is called to generate the response.
- PARENTS
the list of objects visited during traversal without the published object itself, in reverse order. This implies PARENTS[0] is the object visited before the published one and PARENTS[-1] is the root object.
- URL
the request locator without a query string
- URLn, URLPATHn
URLn is the prefix of URL that is obtained by removing the last n path segments. This implies that URL0 has the same value as URL, URL1 is URL with the last path segment removed and so on.
URLPATHn is the path component of URLn.
These variables are often used to construct absolute URLs for objects in the neighborhood.
- BASEn, BASEPATHn
Each BASEn is a prefix of URL. BASE1 is the URL of the Zope Web site's root object. For n>=1, each BASEn+1 is obtained form BASEn by adding the next path segment. If Zope is used via CGI from another Web server, then BASE1 is the URL of the CGI script and BASE0 is obtained from BASE1 by removing the last path segment; otherwise, BASE0 and BASE1 have identical values.
BASEPATHn is the path component of BASEn.
These variables are often used to generate absolute URLs for objects high in the hierarchy or even above Zope (if Zope itself is behind another Web server).
- BODY, BODYFILE
the request body as a string or a file object, respectively.
2.7.1.1.5. Environment data
Environment data, such as HTTP headers, server info and various other pieces of information, can be looked up in the member environ, again a mapping. Many of the items are defined by CGI (Common Gateway Interface), including information from some HTTP headers. Most other HTTP headers are available with a prefix HTTP_ before the HTTP header name and with - translated into _. For example, the HTTP header USER-AGENT can be accessed from Zope under the name HTTP_USER_AGENT. There is also a method, get_header, that allows to retrieve an HTTP header under both its HTTP name and it Zope mangled form.
Most applications will not be interested in these environment data. Therefore, I will not go into details here.
2.7.1.2. Virtual host support
REQUEST provides two methods and a member for virtual host support.
A virtual host is a host that looks and behaves like a normal host: it has its own authority and, apparently, access to a complete Web site. In fact, however, it is only part of a physical host and the virtual host's site is in effect only a subtree in a larger site. Such virtualization requires a bit of magic. Especially, the physical paths in the Zope Web site object are no longer identical with the logical paths used by the Web requests. This may well confuse Zope unless it is informed about the virtualization.
As we have already seen, ZPublisher provides the traversal hook __before_publishing_traverse__. This hook can be used to implement (most of) the virtualization magic. A basic requirement for virtual hosting is the redirection of requests that arrive at the Zope root to the respective root for the virtual host. During traversal, REQUEST keeps in its member path the path segments that still need to be traversed, in reverse order. To redirect the request to a subtree, a hook can simply append the id of the subtree onto path. ZPublisher will then locate the correct virtual host specific object. However, the various request items describing server and URLs will be wrong, unless corrected. REQUEST provides the methods setServerURL and setVirtualRoot to correct this information.
Usually, you would use the SiteAccess product to install a __before_publishing_traverse__ hook. There are HowTos at zope.org that detail how virtual hosting can be implemented with SiteAccess.
SiteAccess can not only be used for virtual hosting but e.g. also for localization and session management. We will use it in our project to identify sessions without the need to use cookies or to explicitly move session ids between query strings and hidden variables.
2.7.2. RESPONSE
RESPONSE can be used by the published object to control the generation of the HTTP response. In most cases, however, the Zope framework's default is satisfactory. The published object will use response methods, when it wants to
set a base URL for relative URI resolution
set an HTTP response header, for example Content-Type or Content-Language to declare the media type or the content language, respectively.
set a cookie
redirect the request to a different URL
set a special response status.
RESPONSE is accessible as request item under the name RESPONSE.
3. Name lookup
A Zope Web site consists of objects. A standard task is to access such objects or their attributes. Zope, like many other systems, uses names for these tasks. The same name can mean different objects in different contexts. Thus, the resolution of names into objects is context dependent. The namespace concept is used to model this fact. A namespace is a device that maps names onto objects.
In Zope, you will have many different kinds of namespaces. We have already met mappings which map keys to values. Often the keys are used as names and the mappings are namespaces. REQUEST and its members other, form, cookies and environ are examples thereof. You will use the subscription syntax to resolve a name into an object for a mapping namespace: mapping[name].
An object is another kind of namespace. It resolves the names of its attributes into the corresponding objects. You will use the attribute access syntax for this kind of resolution: object.name. The attribute access syntax can only be used if the attribute it given by a name literal. If the name is not a literal but computed in some way, then the Python build-in function getattr can be used. It has two mandatory argument, the object and an expression evaluating to the attribute's name. A third optional argument can provide a default value, if the attribute can not be found. If no default is given, an AttributeError would be raised in this case.
These kinds of namespaces are quite common. Zope provides two specific namespace kinds: the DTML namespace and acquisition.
3.1. DTML namespace
The DTML namespace is the namespace implicitly used in document templates for name lookup. It can be explicitly accessed under the name _.
In fact, the DTML namespace is both an object with attributes and a mapping. The mapping is what is implicitly used for name lookup. The attributes provide access to built in objects and functions. You find a list in Zope's online help system.
It will help you to understand the effect of many document template commands, when you know how the mapping part of the DTML namespace is implemented. It is not a flat map, but rather a stack of namespaces, all of them themselves mappings. When you ask the DTML namespace to resolve a name, it asks the top level namespace. If it can resolve the name, that is the result. Otherwise, the next namespace is asked until either the name is resolved or there are no more namespaces on the stack. In the latter case, a KeyError exception is raised.
Figure 3.1. DTML namespace stack
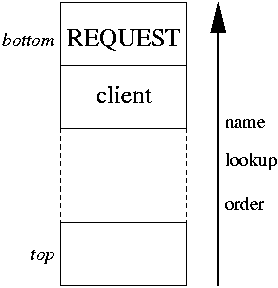
The DTML namespace is a stack of mappings. Mappings are pushed onto the namespace at its top and later popped again. Name lookup starts at the top mapping and proceeds towards the bottom mapping until either the name is found or the bottom is reached.
Many DTML commands which have both a start and end tag push one (or more) namespaces onto the DTML namespace during the execution of their start tag and pop it (them) again during execution of their end tag. We will come back to this during the description of the various commands.
The DTML namespace is not a transparent device. This means, it does not only look up the name and return the associated object (unchanged). Rather, it usually processes the object looked up. This is because the main purpose of the DTML namespace is to support name resolution inside document templates. Document templates should usually generate strings. This implies, everything must finally be converted into a string. Now, most objects have a static, and very unimpressive string representation. It is rarely context sensitive. Therefore, the DTML namespace subscription calls the object, if it is callable. It even knows about some object classes and calls them with adequate argument, for example document templates and Python scripts. If you need the object unprocessed, then you can use the DTML namespace's getitem method. Thus, _[x] calls the object the name of which is given by x, while _.getitem(x) returns the object unprocessed. You need to use the second form, whenever you want to access the object's attributes.
I have said that the DTML namespace is something special in Zope. I lied a bit. Stacks of namespaces are commonly used in all block structured languages. DTML is just another (specialized) block structured language. Its namespace is not so special. Special is, however, that the namespace lookup is not transparent.
3.2. Acquisition
We now come to a powerful, but not easy to understand Zope concept: acquisition.
Usually, an object's namespace is context independent. Thus, if o is an object and name a name, then o.name always yields the same object. Acquisition makes the object's namespace context sensitive. If the object itself cannot resolve the name, then the context in which the object was accessed is asked to resolve the name. This is similar to the DTML namespace. However, while the DTML namespace is a linear sequence, acquisition defines a tree like structure. Let's look at the details.
There are two concepts that play together to implement acquisition: the class ExtensionClass and acquisition wrappers. ExtensionClass was developed by Jim Fulton who also developed Zope and is Zope Corporation's technical director. ExtensionClass is an extension to Python, implemented in C. It defines a Python type. Unlike other Python types, it behaves also like a class. Especially it can create instances and be subclassed. It provides various enhancements for the classes that inherit from it. For example, it allows that methods get attributes and that members are in fact methods (ComputedAttribute). What is relevant for acquisition is a special implementation of attribute lookup. It is no longer transparent. When an attribute a is looked up in an ExtensionClass instance i, then the resulting object o is not simply returned. It is rather checked, whether o has a method __of__. If it has, the attribute lookup result is not o but o.__of__(i). You can read this as "o in the context of i" or "the o of i".
The next important thing are acquisition wrappers. An acquisition wrapper is a class instance with two members (we will see later that there are in fact further members): aq_self and aq_parent. An acquisition wrapper directs attribute lookup first to aq_self, and if this lookup fails, to aq_parent. There are two classes of acquisition wrappers: implicit and explicit ones. Implicit wrappers automatically continue lookup in aq_parent for normal attribute access, while explicit wrappers only do this, if the lookup uses the special method aq_acquire. In the Zope framework, there are two mixin classes Acquisition.Implicit and Acquisition.Explicit, both derived from ExtensionClass, that define __of__ methods. The __of__ constructs implicit or explicit acquisition wrappers, respectively, and put the object into aq_self and the context into aq_parent. Most Zope object classes are derived from Acquisition.Implicit. This implies, they support implicit acquisition. The objects you handle in Zope are usually implicit acquisition wrappers consisting of an object (often another acquisition wrapper) and a context (often another acquisition wrapper, too). As we have explained, the attribute lookup will first look in the object itself and will then look in the context, if necessary. If the result has an __of__ method, then it will again be wrapped with the original wrapper as context.
Figure 3.2. Acquisition wrapper
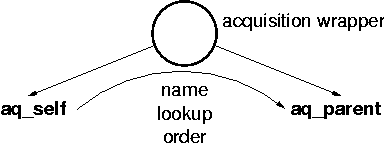
An acquisition wrapper has two components, aq_self and aq_parent. It directs name lookup first to aq_self and if this fails to aq_parent.
Let's see what that means! If you have o=a.b[30], then o will not only have the attributes of b but it appears to have also all attributes of a. It has acquired a's attributes. In the same way, if o=a.b.c, then o can access the attributes of c, b and a. In a Zope Web site, this implies, that whenever you have accessed an object o, then the wrapper returned for o will not only have access to o's attributes but also to all attributes of its ancestors. This is because there must be an access path from the root to o which necessarily contains all of o's ancestors[31]. The wrapper has access to all attributes of objects on this access path and especially that of the ancestors.
Note, however, that the order in which attributes are looked up is not the reverse access order. Let's look at an example. Let's assume, object a has attributes b and c. Let o=a.b. Then o acquires c of a. Call o.c oc. Then oc will have access to all attributes of c, b and a. Let's assume, both a and b have attributes named d. What attribute will oc.d be? It will be (a wrapper for) the one of a and not the one of b. To understand why, we must look, how oc is constructed. o is in fact b.__of__(a). When c is looked up by this wrapper, then first b is asked whether it can resolve this name (we assume not), then a is asked and it responds with c. This lookup in a wraps the result in its context: it yields c.__of__(a). This partial result is then wrapped together with o to yield the final result: (c.__of__(a)).__of__(o). When d is looked up in this wrapper, first its aq_self is asked. This is c.__of__(a). The lookup succeeds as a has the looked for attribute; o and therefore b are not consulted. If neither c nor a had an attribute d, then it would have been looked for in o and the d attribute of b would have been found.
Let's look again, what that means in terms of the Zope Web site structure. Suppose, you have two objects a and b and a accesses b. How does b finds an attribute in this context? It will look, starting from itself towards the root, in search for the attribute. If it fails along this path, it will continue the search in an order that is not easy to describe and finally search it via a. Thus, b has access to any attribute of a, but only if none of its ancestors (itself included) and maybe other intermittent objects has itself an attribute of the given name.
This acquisition feature often confuses Zope users. Acquisition lies between static binding and dynamic binding. With static binding, an object would only see its attributes or that of its ancestors but never that of other objects on the access path. With dynamic binding, the attributes would be looked up in the reverse order of the access path, independent of the ancestors. Acquisition, however, first tries to resolve the name via static binding. If this fails, it looks for the access path but not necessarily in reverse access order as dynamic binding would do.
Jim Fulton, the acquisition's father, called this property "Containment before Context" in his Acquisition Algebra Talk. Acquisition provides access to the attributes of the containing objects, i.e. the object's ancestors, and to the attributes of the access context. Acquisition looks first in the containment and only then in the context. Please, keep this in mind, when you should face an apparently wrong attribute lookup.
4. DTML
DTML (Document Template Markup Language) is a language to describe document templates. A document template is a device for document generation depending on parameters and context. A DTML template consists of literal text with embedded DTML commands. During the document generation, we speak of rendering, the literal text is copied verbatim into the destination document while the commands are executed to produce further text. The produced text replaces the command in the destination document. That means, the generated document is the template with the commands replaced by the text their execution has produced.
4.1. General syntax
When such a template is rendered, it (usually) returns text, most often HTML text although document templates can generate any type of text: plain, HTML, XML, SGML, whatever. A document template consists of literal text intermingled with DTML commands. As the primary target are SGML documents, especially HTML documents, DTML uses SGML syntax to describe its commands: elements, attributes and entity references. This way, document templates look very similar to HTML pages.
Elements, attributes and entities all have names. Elements are delimited by a start and end tag. Usually, they look like <name [attribute_assignment...]>content</name>. There are elements that, by design, must have empty content. For such elements, the end tag can be omitted. For DTML, the end tag of such elements must be omitted. An attribute_assignment usually has the form attribute_name=value. As attribute assignments are separated by white space, value must be quoted, if it contains white space. DTML only allows the double quote character ". DTML allows to omit the attribute_name= part for the first argument, provided that the attribute name would be either name or expr. Quoting of the value determines, whether DTML assumes name (no quoting) or expr (quoting). Many attributes of DTML commands allow to omit the =value part of the attribute assignment. In this case, an attribute specific default value is provided. The names of all elements used as DTML commands consist of the prefix dtml- followed by the command name. Attributes are used to provide parameters for the DTML commands. Many commands render their element content, maybe repeatedly, in a DTML namespace that was specifically enlarged for this rendering.
The content of many commands is structured into various parts by special empty elements. The classical example is the if command. It has the general format
In SGML syntax it might look like with the structuring element dtml-elif optional and repeatable and dtml-else optional.The structuring elements are not used stand alone but only inside the content of the commands they belong to.
4.2. Object argument
Most DTML commands operate on an object. Their result is primarily determined by this object (and the command's content). The object can either be designated by a name or by an expression. In the first case, the object is given by the value of the name, in the second case by that of the expr attribute.
To resolve a name attribute to an object, the name is looked up in the current DTML namespace. This means the object corresponding to name is _['name']. Note that this lookup is not transparent. As we already described, the object determined by direct lookup is called, if it is callable, and the result is the object returned from the call.
Important
This feature confuses many Zope users, as the result is sometimes quite unexpected.
An expr attribute is resolved to an object by evaluating its value as a Python expression. If the expression contains (Python) names, then they are looked up in the current DTML namespace. However, the transparent lookup, provided by the namespace's getitem, is used for this lookup. This means, if name is looked up in an expression, the resulting object is _.getitem('name'). Therefore, the attribute assignments name=name and expr=name sometimes yield the same object but not in general. The resulting object is only the same, if the directly looked up object, i.e. the one returned by the expr attribute, is not callable. With very few exceptions, name=name is equivalent to expr="_['name']".
Note that the value of an expr attribute must be a valid Python expression. Especially, names in such expressions must be valid Python names. A Python name must start with a letter (or underscore) and can consist of letters, digits and underscores. DTML names, on the other hand, have almost no restrictions: they must not start with an underscore and some few names are reserved. This implies that many DTML names are no valid Python names. This is especially the case for DTML names containing a hyphen. A hyphen is used in Python as subtraction operator and especially as name delimiter. What is in DTML a single name is interpreted inside a Python expression as several distinct names combined with the subtraction operator. This often results in NameError exceptions as the name components are not defined individually. This is a bit of a problem for newcomers, as many Zope commands like to use names containing hyphens to provide information for the rendering of their content.
Note that attribute values must be enclosed in double quotes if they contain white space. This is often the case for Python expressions. It is good practice to always enclose the value of the expr in double quotes.
Because of their importance, DTML provides a shorthand notation for the name and expr attributes. The attributename= can be omitted, provided it is the first attribute. Moreover, in such a case, the quoting of the attribute value determines whether the value is interpreted as a name or an expression: if unquoted, it is a name, if quoted, an expression. The omission of the expr attribute is now deprecated as it caused too much confusion, especially among newcomers.
4.2.1. Computed object access
If you know the name of an object, you can simply access the object with the name attribute. However, in some case, the name is not known beforehand: it might be dependent on the runtime context, such as a user input or a loop variable. In these cases, the object name is not constant but computed by a name_expression. You will access such objects with an expr attribute with the value _[name_expression] or _.getitem(name_expression), if you need the object itself and not its rendered value.
Example 3.4. Accessing objects based on user input
Assume, you need to access an object whose name is given by the form variable person. In this case, the name_expression is simply the variable name person. The object would be accessed with _[person] as expr attribute value.
Example 3.5. Accessing object with given name prefix and variable name suffix
Assume, you want to access an object whose name consists of a fixed prefix prefix and a suffix given by the value of a variable suffix. Then your name_expression is the concatenation of the two: 'prefix' + suffix. The expr attribute value _['prefix' + suffix] accesses the object.
4.3. Commands
Most DTML commands have attributes and content. There are a few commands without content. In the following description, commands are described using an abstract synopsis rather than the concrete SGML syntax. Only the most essential commands and attributes are described. The object argument is not described with the exception that it is noted, when the command does not support it.
Some arguments require an explicit value, while most have a default value. Usually, there is a big difference between an argument not mentioned at all and the argument given without a value. In the first case, the operation indicated by the argument is not performed; in the second case, the operation is performed as given by a default argument value.
4.3.1. var: inclusion
The var command is used to include its object argument. The object value is processed as described by a set of optional arguments and, if necessary, converted to a string through the built-in Python str function. The command has no content.
4.3.1.2. Arguments
Arguments are optional with the exception of the object argument (of course).
- fmt
specifies a format for converting the object's value into a string. A default value is defined, but it will raise an exception (a bug).
There are 3 kinds of formats: C formats, custom formats and special formats.
C formats are the format strings originally defined for the programming language C. A C format is a string consisting of literal text and intermingled conversion specifications. A conversion specifications has the form %[flags][minimum width][.precision][length modifier]conversion specifier. A conversion specifier is often called a format character as they are single characters. The format characters c, i, d, u, o, x and X convert an integer into a string. d, o, x and X use the decimal, octal and hexadecimal number representation, respectively. x and X use lower and upper case letters, respectively, for hex digits a through f. i is a synonym for d, u interprets the integer as unsigned and c as a character code and converts to the corresponding character. e, E, f, g and G call for different floating point formats. s integrates a string. Flags control alignment, padding and some format details. The precision controls the maximal field width for s, the minimal number of digits for integer formats and the number of significant digits after the decimal point for floating point numbers. See a C reference for details. Python has extended the C formats. The following description is copied from the Python Library Reference.
The following format characters are understood: %, c, s, i, d, u, o, x, X, e, E, f, g, G. Width and precision may be a * to specify that an integer argument specifies the actual width or precision. The flag characters -, +, blank, # and 0 are understood. The size specifiers h, l or L may be present but are ignored. The %s conversion takes any Python object and converts it to a string using str() before formatting it. The ANSI features %p and %n are not supported. Since Python strings have an explicit length, %s conversions don't assume that '\0' is the end of the string.
For safety reasons, floating point precisions are clipped to 50; %f conversions for numbers whose absolute value is over 1e25 are replaced by %g conversions. All other errors raise exceptions.
If the right argument is a dictionary (or any kind of mapping), then the formats in the string must have a parenthesized key into that dictionary inserted immediately after the "%" character, and each format formats the corresponding entry from the mapping.
C format examples are %5d, %-5d, and %.3d which convert 12 into the strings " 12", "12 " and "012", respectively.
A custom format is any method of the object argument (maybe acquired) that can be called without arguments. The method result is converted into a string, if necessary.
There are a few special formats. Most of them you will not need as their effect can be obtained easily and much more general with C formats and other var attributes. An exception is structured-text. It converts the object argument's value into a string, interprets this string as a structured text[32] and converts it into HTML.
- missing
This attribute only has an effect, if the object argument is specified by a name attribute. Usually, a KeyError exception is raised, when the name lookup fails. However, if a missing attribute is present, then its value is returned instead. Its default value is the empty string.
- null
If present, its value is substituted for the object arguments value in case this is null. Any Python false value, e.g. the empty string, None, the empty list, tuple or dictionary, with the exception of the number 0 is interpreted as null.
This argument may be useful to handle null database fields. Its default value is the empty string.
- lower, upper, capitalize
convert to lower or upper case or capitalize, respectively. Capitalizing means converting the first character to upper case and all other characters to lower case.
- spacify
converts underscores into spaces.
- newline_to_br
converts newlines into <br>.
- html_quote, sql_quote, url_quote, url_quote_plus
quotes the object argument's value as is necessary for the respective context. url_quote, for example, quotes characters which are illegal or have special meaning in URLs. The difference between url_quote and url_quote_plus is that the latter converts spaces into plus characters. This is necessary for names and values that occur in the query string. It must not be used elsewhere.
The value of these arguments is not used. Only there presence counts.
- size, etc
These arguments allow to limit the size of the included value. If the value would be larger then size, then it is truncated to at most this length (truncation prefers to occur after a space) and the value of etc, or ... if not present, is appended.
The default value of size and etc are 0 and ..., respectively.
- url
causes the object argument's URL to be included rather than its value.
This argument is special, as even a name attribute is transparently looked up: it is not called (even if callable) unlike the usual treatment of name attributes.
4.3.1.3. Examples
- <dtml-var x>
includes the value of x. x is looked up in the current DTML namespace, called, if it is callable, and the result converted to a string.
- <dtml-var expr="x+y">
includes the value of x+y.
- <dtml-var x html_quote missing>
includes the value of x with the special HTML characters < and & quoted. If x is not bound in the current DTML namespace, no KeyError is raise but the (default) value of missing, the empty string, is included.
- <dtml-var x url>
includes the URL of x.
4.3.2. Entity reference: inclusion
Entity references provide an alternative to the var command. There primary use is inclusion into HTML attribute values. Therefore, they perform by default HTML quoting.
4.3.2.1. Synopsis
In principle, entity references do not form a new command, but are the var command in an alternative syntactic disguise. Therefore, we describe here the concrete syntax while we use the abstract synopsis elsewhere in this chapter.
&dtml[.argument]...-variable;
If no argument is given, a default argument of html_quote is assumed.
This above entity reference is equivalent to
<dtml-var variable [argument]...>
4.3.2.2. Examples
- &dmtl-URL;
inserts the (request) URL, html quoted.
- &dmtl.url_quote-URL;
inserts the (request) URL, url quoted. Note, that it is usually wrong to url quote a complete URL as this will quote the component separators. Only separate URL components should be url quoted.
- &dmtl.-URL;
inserts the (request) URL, not quoted.
4.3.3. if: conditional
The if command provides for conditional rendering of a part of its content. Its content can be structured with optional and repeatable elif commands and an optional else command. if and elif have an object argument but no other arguments; else does not have arguments.
4.3.3.1. Synopsis
The if evaluates its object argument. If it evaluates to a Python true value, then the true_body is rendered. Otherwise, the object argument of each successive elif is evaluated until one evaluates to true. In this case, the corresponding elif_body is rendered. If no elif object argument evaluates to true, then the optional else_body is rendered.
Note
If an object argument is specified via the name attribute, then no exception is raised, if the name is not found. Rather, this is simply interpreted as false. Thus, for an if or elif, the attribute assignment name=variable is equivalent to the attribute assignment expr="_.has_key('variable') and _['variable']". You may need this equivalence, when you want to check more complex conditions, such as joint trueness of two variables.
Note
If an object argument is specified via the name attribute, then the evaluated variable's value is cached in the DTML namespace. The objective is to save time when the variable referenced a computationally costly method; caching ensures that the method is called only once even if the variable is accessed repeatedly. However, this caching changes the value's type. If the variable is later looked up transparently, surprises may arise, usually in the form of AttributeError exceptions.
4.3.3.2. Examples
Example 3.6. Checking for variable existence
<dtml-if message> <div class="message"><dtml-var message></div> </dtml-if>
This DTML fragment checks whether message exists and has a true (usually nonempty) value. If it does, the message is rendered.
I like this form to provide action feedback: when a form action has been executed, the response returns the original form but with an additional message parameter. This message is rendered with code similar to the above to inform the user about success or failure.
Example 3.7. Success/Error messages
<dtml-if message>
<dtml-if "message[0]">
<div class="error"><dtml-var "message[1]"></div>
<dtml-else>
<div class="success"><dtml-var "message[1]"></div>
</dtml-if>
</dtml-if>
This is a bit more elaborated then the example before. The fragment assumes, that message, if defined, is a pair. The first component signals success or failure, say with an error code. The code 0 indicates success, everything else failure. The second component contains the human readable success or error message.
4.3.4. unless: conditional
unless is a shorthand for a negated if.
4.3.4.1. Synopsis
unless renders unless_body if its object argument evaluates to a Python false value. If the object argument was specified by a name attribute, then unless_body is also rendered, if the name lookup failed.
is equivalent to4.3.4.2. Examples
<dtml-unless names>
<dtml-call "REQUEST.set('names',())">
</dtml-unless>
This fragment checks whether names has a (non false) value. If this is not the case, it gives it the value (), the empty tuple.
You may use code like this to provide a value for form variables corresponding to multiple selections. As detailed earlier, such variables are not defined during form submission when no option is selected.
4.3.5. in: iteration
The in command iterates over a sequence of objects and renders the iteration_body for each object. For each iteration, it extends the DTML namespace with information about the current object and the state of the iteration. After the iteration, the original DTML namespace is restored.
The sequence iterated over is specified by the command's object argument. This implies that this argument must evaluate either into a Python false value (this includes empty sequences) or into a sequence, e.g. a list, tuple or other sequence like objects such as database or catalog query results. If the result is a Python false value, then an optional else_body is rendered.
If the sequence is large, you may not want to iterate over it in a single go but do it in several batches where each batch iterates over a sequence segment. in supports such batching: it allows to specify a starting index and the maximal number of iterations to be performed, it provides information about the existence of previous and following batches and it facilitates the construction of links to these batches.
What you often will do with sequences: provide running counts or additions at the end of the sequence. in supports this and a complete bunch of other statistical evaluations.
4.3.5.1. Synopsis
Note
If an object argument is specified via the name attribute, then the evaluated variable's value is cached in the DTML namespace. The objective is to save time when the variable referenced a computationally costly method; caching ensures that the method is called only once even if the variable is accessed repeatedly. However, this caching changes the value's type. If the variable is later looked up transparently, surprises may arise, usually in the form of AttributeError exceptions.
Note
The else may carry a name attribute. This does not have a semantic significance. However, it may help to detect and locate misplaced else clauses.
4.3.5.2. Arguments
in arguments fall into three classes: one argument that controls the namespace extension, several arguments that control the iteration order and several batching arguments.
4.3.5.2.1. Namespace extension control
For each iteration, the current object is pushed onto the DTML namespace. Usually it is wrapped in an InstanceDict. This wrapper implements the mapping subscription (which is used during namespace lookup) by the wrapped object's attribute lookup. This makes the object's attributes accessible inside the iteration_block.
However, if the current object is already a mapping, you probably will be more interested in the object's keys rather than its attributes. In this case, you would use the mapping argument. If it is present, the object argument is interpreted as a sequence of mappings and the current object is pushed unwrapped onto the DTML namespace. Its keys, rather then its attributes, are then accessible inside the iteration_block.
4.3.5.2.2. Iteration order control
in provides a set of arguments that control the iteration order. The sequence can be sorted (and) or reversed before the iteration.
- sort
If present, the sequence is sorted, before the operation starts. If no value was given or if the value is a Python false value, then the sequence is simply sorted using the standard Python sort function. Otherwise, sort's value should be a comma separated list of key names. The sequence is sorted with respect to the values of these keys. If such a value happens to be callable, then it is tried to call it without parameter. If this succeeds, then the result is used for the comparison otherwise the original value.
- sort_expr
If present, its value is interpreted as a Python expression. The expression is evaluated to define a sorting specification. Sorting is performed as was described for sort.
If both sort and sort_expr are specified, sort_expr takes precedence.
- reverse
If present, then the sequence is reversed after the optional sorting and before the iteration starts.
- reverse_expr
If present, its value is interpreted as a Python expression. If its evaluation yields a Python true value, then the sequence is reversed after the optional sorting and before the iteration starts.
If both reverse and reverse_expr are present, reverse_expr takes precedence.
- skip_unauthorized
Usually, an Unauthorized exception is raised when the sequence contains an element the current user has no access rights for. If skip_unauthorized is given, then such elements are silently filtered out.
4.3.5.2.3. Batch control
Batch support is enabled if any of the arguments start, end or size is present. A batching argument's value may either be an integer constant or a name. In the latter case, the name is looked up and converted into an integer, if possible.
- start, end, size
specify the requested starting (inclusive) and ending (exclusive) number of the sequence elements that should be iterated over. in silently truncates the range, if it exceeds the sequence. Depending on the orphan parameter, in may also increase the range near the sequence start and end in order to avoid orphans.
start and end are 1 based numbers, e.g. start=1 means, start with the first sequence element.
If the range is under or over specified then useful defaults are provided or the values are silently reconciled, respectively.
- orphan
tells in to try to avoid batches which do not have at least this size. in silently increases a batch size near the sequence start or end, if the previous or next batch, respectively, would violate the orphan restriction.
Note
orphan was automatically defined with the value 3 until Zope 2.4. You had to explicitly specify orphan=0, if you did not want the automatic batch increase.
- overlap
controls, how many elements successive batches should overlap.
- previous, next
The presence of one of these attributes completely changes how in works. It no longer iterates over the sequence. Instead it renders the iteration_body once, if there is a previous or next batch, respectively. Otherwise, it renders the optional else_body. For the iteration_body rendering, the DTML namespace is extended with batch information.
4.3.5.3. Defined names
in defines myriads of names for the rendering of iteration_body. These are, highest precedence first, the current object's attributes or, if mapping is given, keys, a set of so called sequences variables and the name used as the name attribute value, if any. The set of sequence variables consists of various classes providing information about the current iteration step, batches, grouping, the sequence itself and statistics.
4.3.5.3.1. Iteration step variables
These variables describe the current iteration step: the current index (0-based), number (1-based), the relation with the current batch (at start, end) and so on.
- sequence-item, sequence-key
Usually, sequence-item is the current object and sequence-key raises a TypeError exception. If, however, the current object happens to be a pair, i.e. a tuple with two elements, then sequence-key is the first and sequence-item the second element in the pair[34].
- sequence-start, sequence-end
has a true value, if this iteration step is the first or last, respectively, in the current batch.
- sequence-index
the index of the current iteration step.
The index is a 0-based number: the first sequence element has the index 0.
- sequence-number, sequence-letter, sequence-Letter, sequence-roman, sequence-Roman
the number of the current iteration step, in various encoding. For example, number: 1, 2, 3; letter: a, b, c; Letter: A, B, C; roman: i, ii, iii.
- sequence-even, sequence-odd
returns true, if the current index is even or odd, respectively.
These variables can be used to shade successive table rows differently.
4.3.5.3.2. Batch variables
Batch variables provide information about one or several batches. They are usually only defined under some circumstances: e.g. in commands with the previous or next arguments, at the start or end of a batch.
- sequence-step-start, sequence-step-end, sequence-step-size, sequence-step-orphan, sequence-step-overlap, sequence-step-start-index, sequence-step-end-index
They describe the current batch. They are always defined if batching is enabled.
- previous-sequence, previous-sequence-start-index, previous-sequence-end-index, previous-sequence-start-number, previous-sequence-end-number, previous-sequence-size
describe the previous batch. They are only defined if the previous argument is present and during the first iteration in a batch[35].
- next-sequence, next-sequence-start-index, next-sequence-end-index, next-sequence-start-number, next-sequence-end-number, next-sequence-size
describe the next batch. They are only defined if the next argument is present and during the last iteration in a batch[36].
- previous_batches, next_batches
returns a list describing the previous or next batches, respectively. Each list element is a dictionary with the keys batch-start-index, batch-end-index, batch-start-number, batch-end-number, batch-size and mapping and describes the corresponding batch. This information is only defined, if previous-sequence and next-sequence, respectively, is defined and true.
4.3.5.3.3. Grouping variables
Sometimes, sequence elements should be grouped with respect to the value of a field with a special header or trailer at the start or end of such a group, respectively. Grouping variables are used for this purpose, usually together with a sort specification for the respective field.
- first-variable, last-variable
returns true, if this is the first or last element, respectively, of a group defined with respect to variable. This means, first-variable is true in the current iteration, if this is the first sequence element or if the previous sequence object has a different value for variable variable. last-variable behaves symmetrically.
4.3.5.3.4. Sequence variables
These variables provide information about the sequence or the in command as a whole.
- sequence-length
the length of the sequence.
- mapping
true, if the sequence elements are treated as mappings
- sequence-query
the query string with the parameter definition removed that is used for the start value.
This variable facilitates the creation of links to other batches.
Note
This variable is only useful for GET requests; it is empty for POST requests.
4.3.5.3.5. Statistics variables
These variables provide statistical information about the values of a given variable in the complete sequence. The name of the target value is given as suffix of the statistics variable name. Sequence elements where the target variable have the value None or missing are skipped for the statistical evaluation.
The following statistical variables are defined: total-variable, count-variable, min-variable, max-variable, median-variable, mean-variable, variance-variable, variance-n-variable, standard-deviation-variable, standard-deviation-n-variable.
4.3.5.4. Examples
<dtml-in objectValues> <dtml-var title_and_id><br> <dtml-else> The folder is empty. </dtml-in>
Example 3.10. Sorted batched folder listing
<dtml-in objectValues start=start size=20 sort=id>
<dtml-if previous-sequence>
<p>
<a href="<dtml-var URL
><dtml-var sequence-query
>&start=<dtml-var previous-sequence-start-number>"
>Previous <dtml-var previous-sequence-size> objects</a>
</p>
</dtml-if>
<dtml-var title_and_id><br>
<dtml-if next-sequence>
<p>
<a href="<dtml-var URL
><dtml-var sequence-query
>&start=<dtml-var next-sequence-start-number>"
>Next <dtml-var next-sequence-size> objects</a>
</p>
</dtml-if>
<dtml-else>
The folder is empty.
</dtml-in>
Example 3.11. Shopping card presentation
<dtml-in shopping>
<dtml-if sequence-start>
<table cellspacing=10 width=80% align=center>
<tr>
<th align="left">Article</th>
<th align="right">Price</th>
</tr>
</dtml-if>
<tr <dtml-if sequence-even>style="bgcolor=#c0c040"</dtml-if>>
<td><dtml-var article></td>
<td align=right><dtml-var price fmt="$%.2f"></td>
</tr>
<dtml-if sequence-end>
<tr><td colspan=2><hr></td></tr>
<tr>
<td>Total</td>
<td align=right><dtml-var total-price fmt="$%.2f"></td>
</tr>
</table>
</dtml-if>
<dtml-else>
Your shopping basket is empty!
</dtml-in>
4.3.6. call: calling
call is very similar to var. It locates and evaluate its object argument in the same way as var would do. But then, it discards the resulting value and does not include it. This is useful for calling methods that do not return a value (which in Python means, they return the value None) or whose return value would be inappropriate in the current context.
The command has no content and no arguments besides the object argument.
4.3.6.1. Examples
Example 3.12. Setting a request variable
<dtml-call "REQUEST.set('variable',15)">
This fragment calls REQUEST's set method to give variable the value 15. It discards the method's None return value.
Example 3.13. Call management functions
<dtml-call "manage_changeProperties(REQUEST)">
This fragment calls the management function manage_changeProperties. Most management functions return a management tab as result. This is appropriate, if the function is called inside the management interface. However, if you call them explicitly, you likely want to provide your own response. In this case, you can use call to call the method but discard its unwanted return value in order to provide your own response.
4.3.7. let: namespace control
let pushes a new mapping unto the DTML namespace containing its attribute assignments and then renders its content. After that, the original namespace is restored.
let does not have an object argument.
4.3.7.2. Arguments
let accepts arbitrary arguments. They are specified by attribute assignments in the start tag. Neither attribute name nor attribute value may be omitted. The attribute assignments make up the mapping pushed by let onto the DTML namespace. If an attribute value is enclosed in double quotes, then the value is evaluated as a Python expression in the same way as the value of an expr attribute would be. Otherwise, the value is treated as a name and looked up as a name attribute value would be. Especially, looked up objects are called if they happen to be callable.
4.3.7.3. Examples
Example 3.14. Caching expensive results
<dtml-let query_result=queryDatabase
hits="_.len(query_result)"
>
<p>
<dtml-if hits>
Your query resulted in <dtml-var hits> hits.
<dtml-if "hits > 10">
The first ten are shown below.
<dtml-else>
They are shown below.
</dtml-if>
<dtml-in query_result size=10>
....
</dtml-in>
<dtml-else>
Your query did not yield any hits.
</dtml-if>
</p>
</dtml-let>
In this example, queryDatabase is (envisaged to be) a Z SQL method querying a database. Querying a database is quite expensive. Thus, it is useful to cache the result. This is done above with the query_result=queryDatabase attribute assignment. It calls queryDatabase and assigns the result to query_result. This result is then used twice, once to determine the number of hits and once by the in command.
Note
Note that the caching would not have taken place, if the attribute assignment had the form query_result="queryDatabase". In this case, the method queryDatabase itself would have been assigned to query_result and not the result of calling it.
In the example, we have also defined the variable hits. This was not motivated by significant time savings but to make the template code clearer.
Example 3.15. Renaming variables
<dtml-in seq>
<dtml-let index=sequence-index>
...
<dtml-var expr="pseq[index]">
...
</dtml-let>
</dtml-in>
The example renames sequence-index, which is difficult to use inside Python expressions, to the valid Python name index.
Note
Note that it might be dangerous to do the same for sequence-item. If the object happens to be callable, which is not the case for sequence-index but might be the case for sequence-item, then not the object itself but the result of calling it is assigned to the new name.
Example 3.16. Providing parameters for DTML objects
<dtml-let name="'Charles'" age="57"> <dtml-var showPerson> </dtml-let>
This example shows one way to pass arguments name and age to showPerson, provided showPerson is a DTML object (or another object called with the DTML namespace). An alternative way would be
<dtml-var "showPerson(_.None,_, name='Charles', age=57)">The first two (magic) arguments are necessary to pass the DTML namespace, _, into the called showPerson.
4.3.8. with: namespace control
with pushes its object argument onto the DTML namespace for the rendering of its content. This is useful, to access the attributes of objects that are not in the current acquisition context, or to explicitly control the lookup order.
4.3.8.2. Arguments
- mapping
indicates that the object argument should be treated as a mapping. Its keys rather than its attributes are made available via the DTML namespace.
- only
indicates, that a new namespace should be created which only contains the attributes (or keys) of the object argument. The original DTML namespace is ineffective for the rendering of with_body.
4.3.8.3. Examples
Example 3.17. Accessing folder contents
Assume you have collected images in a folder images in the root folder. While the folder images is reachable via acquisition, its content is not. The following fragment makes its content accessible:
<dtml-with images> ... <dtml-var image1> ... <dtml-var image2> ... </dtml-with>
Example 3.18. Form data processing
<dtml-with "REQUEST.form" mapping> ... <dtml-var form_variable1> ... <dtml-var form_variable2> ... </dtml-with>The example above demonstrates how you can rather safely access form variables. Although the REQUEST variables are directly accessible through the DTML namespace, they are at the bottom of the namespace stack. This implies, they can easily be hidden by names higher up. The with above brings REQUEST.form at the namespace's top.
There are still some lingering problems. As HTML does not send data sets for unsuccessful form controls, REQUEST.form will not contain definitions for such unsuccessful controls. If we are unlucky, somewhere on the namespace the name may be defined. We get this value and might think it came from the request. The following fragment fixes handling for a potentially unsuccessful multiple selection:
<dtml-unless "REQUEST.form.has_key('selection')">
<dtml-call "REQUEST.form.update({'selection' : (), })">
</dtml-unless>
Note
I was tempted to use the only argument to achieve this. However, this argument is almost unusable. You probably should forget about it.
4.3.9. tree: interactive hierarchical display
The tree supports the interactive display of hierarchical structures, similar to the Window's explorer. Hierarchy nodes can be interactively expanded and collapsed again. If expanded, the node's children are displayed which, in turn, can be expanded further unless they are leaf nodes.
The tree command provides an easy and intuitive way to browse hierarchical information.
Usually (unless the argument single is present), tree remembers its state in a cookie named tree-s. This implies that cookies must be enabled and that a single page can contain at most one tree.
tree uses an HTML table to present the hierarchical structure. With the exception of the last column, all columns are 16 pixels wide. Each table row consists of sufficient blank columns to reflect the current hierarchy level, an icon column with a plus or minus icon or blank and then a large column spanning to the end of the row with the rendered tree_body. The icon column reflects whether the node is expandable, collapsible or a leaf, respectively. Clicking on the icon performs the corresponding action.
4.3.9.2. Arguments
- branches, branches_expr
The name of a method or an expressions, respectively, to determine the hierarchy children of a node. The branches default is tpValues. For most standard Zope objects, it returns the empty tuple; for folders it returns the list of sub folders.
- sort
the name of an attribute (member or parameterless method) with respect to which the children of a node should be sorted.
- reverse
calls for the reversal of children order (after sorting)
- skip_unauthorized
do not raise an Unauthorized exception for children that cannot be accessed (due to insufficient permissions). Rather, ignore them silently.
- nowrap
truncate rather than wrap the rendered tree_body, if it does not fit the available space.
- leaves
the id of a DTML object (method or document) used to display leaf nodes.
- expand
the id of a DTML object (method or document) used to display non-leaf nodes.
- header, footer
the id of a DTML object (method or document) displayed before or after an expanded children list, respectively.
- single
ensure that at most one branch is expanded.
In this mode, the tree does not use cookies to remember its state (as it otherwise does).
- assume_children
determine the branches of a node only, if the node should be expanded. Assume, a node has children without checking.
Usually, tree determines the branches also to show whether a node is expandable or not. With this argument, all nodes are shown as expandable. The argument is primarily there to avoid expensive branch determination.
- urlparam
specify a value to be included in the query string of the hierarchy control URLs.
- id, url
method names to determine the id or URL of a node, respectively.
4.3.9.3. Variables
tree pushes the current hierarchy node and a set of tree variables onto the DTML namespace in order to render tree_body. The following tree variables are defined:
- tree-colspan
the total number of columns
- tree-level
the current level, counting from 0.
- tree-item-url
the current node's URL relative to that of the hierarchy root
- tree-item-expanded
true, if the current item is expanded
- tree-root-url
the last path segment of URL
- tree-state
the tree's state, a complex list structure describing the expanded branches
4.3.9.4. Expansion control
The tree's expansion can be controlled through the following set of DTML variables:
4.3.9.5. Examples
Example 3.19. Displaying the subtree rooted in the current object
<dtml-tree branches=objectValues>
<dtml-if icon>
<a href="&dtml-tree-item-url;" target=display>
<img src="&dtml-icon;" border=0 alt="&dtml-meta_type;">
</a>
</dtml-if>
<a href="&dtml-tree-item-url;" target=display>
&dtml-title_or_id;
</a>
</dtml-tree>
Example 3.20. Simple book display
<dtml-tree book branches_expr="objectValues(['Folder', 'DTML Document'])
sort=position leaves=showLeaf>
<dtml-var title_or_id>
</dtml-tree>
This fragment provides a simple interactive book display, provided the sections and subsection are contained in the folder book. The property position controls how the children of a node are linearized. The folder may contain other objects; only folders and DTML documents are taken into account (due to the branches_expr value). The DTML method showLeaf can look like this:
<dtml-var standard_html_header> <dtml-var "_.render(this())"> <dtml-var standard_html_footer>
this returns the current object, render renders it.
4.3.10. try: catching exceptions
Usually, ZPublisher catches any exceptions and generates error responses for them. The try command allows you to take over the handling of all or selected exceptions.
The command has a second variant. This variant supports the implementation of cleanup code, code that is executed both if an exception occurred as well as during normal operation.
4.3.10.1. Synopsis
This form of the command renders the try_body. If this raises an exception, try looks successively whether one of its except subcommands can handle the exception. In this case, it renders the corresponding except_body and forgets about the exception. If rendering try_body does not raise an exception, the optional else_body is rendered.
This form renders try_body and then finally_body. finally_body is even rendered when try_body raised an exception. In this case, the exception is suspended during the rendering of finally_body and then reactivated.
You will use this features to ensure proper cleanup for sensitive resources.
4.3.10.2. Arguments
Only except accepts any arguments. Each of its arguments specifies the name of an exception or an exception class this except clause handles. If the except does not have arguments, it handles any exception.
4.3.10.3. Variables
except extends the DTML namespace with 3 variables describing the handled exception
4.3.10.4. Examples
Example 3.21. Application specific error handling
<dtml-try>
<dtml-with "_.namespace(REQUEST=REQUEST)" only>
<dtml-with REQUEST mapping>
<dtml-let object__="PARENTS[0]">
<dtml-with "object__">
<dtml-var object__>
</dtml-with>
</dtml-let>
</dtml-with>
</dtml-with>
<dtml-except>
<dtml-call "RESPONSE.setStatus(error_type)">
<html>
<head>
<title>Error</title>
</head>
<body>
<h1>Error occurred</h1>
<p>
Error type: <dtml-var error_type><br>
Error value: <dtml-var error_value>
</p>
<h3>Traceback</h3>
<dtml-var error_tb>
</body>
</html>
</dtml-try>
This code can go into a DTML method. If its id is appended to an URL, it will have a similar effect to calling this URL directly[37], but any exceptions are caught and handled in the except clause.
Note
You would not implement general application specific error handling in this way. You would rather customize the object standard_error_message.
4.3.11. raise: raising exceptions
raise allows you to raise an exception.
4.3.11.2. Arguments
raise has a single argument, type. When rendered, raise raises an exception with the type given by the type argument and the value given by its content.
4.3.11.3. Examples
Example 3.22. Validation error
<dtml-unless check>
<dtml-raise type="ValidationError">
You request is not valid
</dtml-raise>
</dtml-unless>
<dtml-if "AUTHENTICATED_USER.getUserName() != 'Anonymous User'"> <dtml-raise type="Unauthorized">To logout, please submit the login dialog without entering a password.</dtml-raise> <dtml-else> <dtml-var standard_html_header> <p>You are now logged out.</p> <dtml-var standard_html_footer> </dtml-if>
It is quite difficult to log out when HTTP authentication is used. This is because the authentication information is controlled by the browser and Zope has only very limited control over it. The only way for Zope to invalidate the authentication information is to send an Unauthorized response. This is done by raising the Unauthorized exception, as shown above. When the browser receives an Unauthorized response, it pops up the login dialog. This is not what we want when the purpose is to log out, but there is no way around it. If the user now enters any invalid login information, e.g. keeps the password empty, and submits the dialog, the user is effectively logged out from Zope.
4.3.12. return: returning value
Usually, document templates are used to generate a document, i.e. a string. The return command allows a document template to return an arbitrary value, the text produced so far is discarded.
The return command aborts the template rendering, discards any generated text and returns the value of its object argument.
This command was useful before the Zope script objects were designed. It helped to implement logic in DTML. Now, you will rarely use this command as logic is far better implemented in scripts.
4.3.12.2. Examples
Example 3.24. Form configuration
<dtml-return "[
{'label' : 'Name', 'control' : 'text', },
{'label' : 'Email', 'control' : 'text', },
{'label' : 'Interest', 'control' : 'selection', 'multiple': 1,
'options' : ((1,'Sports'), (2,'Art'), (3,'Music'), (4,'Film'), (5,'Journeys')),}
]">
The fragment above can be used as a form configuration. It returns a list of form control descriptions. Each description is a dictionary that defines attributes, content and label for the respective control.
<dtml-unless Name> <dtml-return "'You must specify a name'"> </dtml-unless> <dtml-unless Password> <dtml-return "'You must specify a password'"> </dtml-unless> <dtml-if "Password != Password_retyped"> <dtml-return "'The Password and retyped Password must be identical'"> </dtml-if> <!-- successful --> <dtml-return "0">
The fragment above checks that the form fields Name and Password are non-empty and that Password and Password_retyped have the same content. If the check fails, a corresponding error message is returned. Otherwise, 0 is returned to indicate success.
4.4. Calling DTML objects
Document templates are executed, or rendered, by calling them. They accept two optional positional arguments, called client and REQUEST, and arbitrary many keyword arguments. They use their arguments to build an initial namespace and then render the template in this namespace. Logically (though not physically), the namespace is constructed as follows:
Build a new, empty namespace.
If REQUEST is not None, push it onto the namespace.
If client is not None, it must be an object or, for a DTML method, a tuple of objects. Each of these objects is pushed onto the namespace, wrapped in an InstanceDict (which makes its attributes accessible by namespace lookup). A DTML Document pushes itself, more precisely, its explicit acquisition wrapper, onto the namespace, too.
If there are keyword arguments, they are pushed onto the namespace as a single mapping.
When a DTML object is called implicitly during namespace lookup, through namespace subscription or via the namespace method render, the namespace recognizes it as a DTML object by its member isDocTemp. It will call objects with a true isDocTemp with 2 arguments, None and itself. This means, with client=None and REQUEST=_. This passing of the namespace as REQUEST parameter ensures that the called DTML object has access to the callers context. For a DTML method, nothing else is available as context. A DTML document can use its own context, in addition. When you call a DTML object explicitly, either inside a Python expression in DTML or inside a Python script or external method, you need to ensure that it gets the necessary arguments. While trivial DTML objects do not need any arguments or only keyword arguments, it is very likely that more complex ones require at least a namespace or a client. Watch out for missing arguments when you get unexpected KeyErrors or NameErrors.
5. Site management
A Zope site is usually managed through the Web. However, all management functions can also be performed programmatically. As the management functions can be called via HTTP, many operations can be controlled automatically from outside Zope. Besides, content can also be partially managed via FTP (File Transfer Protocol) or WebDAV (WEB Distributed Authoring and Versioning).
5.1. Through the Web management
A Zope site is usually managed through the Web by means of a Web browser. Each object has a Web callable method manage. It displays a frameset or page used to manage this object: view the object, its contents, properties and change any of these aspects. The information is usually organized into a set of views, such as Contents, View, Properties, Security, History, Undo, Find. Each view provides access to a set of related items associated with the object. The Properties view, for example, displays the object's properties, allows to define new properties and to edit or delete current ones. The Contents view displays the objects contained in an ObjectManager, allows to add new objects and manage or delete existing ones. Sometimes different views show related information but process them differently. For example, the view and edit views of DTML objects both show the associated DTML template. However, view renders the template while edit shows the source in an editable HTML textarea.
The available views are shown as tabs on the management pages. Standard tab selection is used to switch between views. To use a view, a user must have a view specific permission. The management interface shows just the views the current user is entitled to use.
While most objects have just the Web management interface as described: a set of views selectable through tabs at the top of each view, you will usually see a different interface. The interface of object managers consists of two frames. The right frame contains the views display, at described above. The left frame visualizes all the ObjectManager sub objects directly or indirectly contained in the object as an interactively explorable hierarchy. This hierarchy display is implemented through a DTML tree command. It provides fast access to these object managers. Clicking on one of them shows the default view in the right frame.
The management interface is documented in the embedded Zope help system. Each view has a help button in the upper right corner. It opens the Zope online help window with the description of the current view: its form controls and the possible actions.
5.2. Programmatic Management
All views and management interface actions are implemented through methods of the managed object. By convention, most of them have names starting with manage_. The available methods are of course type specific. These methods can be called from DTML templates and scripts as well as via the Web.
There is currently no good and complete documentation about the available management functions. Some of them, actually few, are documented in the API section of the embedded Zope online help. Fortunately, Zope is open source and its source is documented quite well. The available views of an object are defined by the class member manage_options. It is a tuple of dictionaries. The dictionaries usually have keys label, action and help. They define the label to be used in the management interface tab, the method name implementing the view and the help page documenting the view, respectively. Most standard Zope objects are defined in the (Python) package OFS, their sources can be found in the (file system) folder lib/python/OFS. Some objects are defined in products. Their sources can be found in lib/python/Products/productname.
Another useful resource is __ac_permissions__. It defines the permissions necessary to call methods or access the object's members. It is a tuple of tuples. Each tuple describes one permission the name of which is given as first component. The second tuple field is a tuple of method names. These are the methods controlled by the permission. A user must have this permission to be able to call the method. An empty method name indicates access to the object's members. The optional third tuple field is a tuple of roles. These roles have the permission by default; it can be overridden through the management interface. Thus, the second tuple component shows you the methods that can be accessed through the Web. These include all management functions. You must keep in mind, that permission specifications can be inherited from base classes. Thus, to get a list of all management functions, the base classes must be explored, too.
The views are usually implemented through file system based DTML objects collected in a dtml sub folder. Most standard Zope objects are defined in the (Python) package OFS, thus most DTML files are located in lib/python/OFS/dtml. Some objects are defined in products. Their view definitions can be found in lib/python/Products/productname/dtml. It is quite instructive to explore how Zope's management interface is implemented, especially when you want to do similar thing programmatically.
Once, you have determined the appropriate method and its parameters, you can call it with the DTML call command from DTML or directly from a script.
After I wrote this, I was convinced their must be a better way to find out about the available management functions and how to call them. My answer was a small product DocFinder. DocFinder allows you to ask Zope about the documentation for any of its objects. The documentation contains the available attributes, the roles allowed to access them, the arguments provided the attribute is a method and a documentation string, if provided by the implementer. It gives you a very clear overview about the object's infrastructure and how it was build from Zope's various building blocks. Take a look at it.
Example 3.26. Changing properties
Properties can be changed with the PropertyManager's method manage_changeProperties. Its source documentation tells:
def manage_changeProperties(self, REQUEST=None, **kw):
"""Change existing object properties.
Change object properties by passing either a mapping object
of name:value pairs {'foo':6} or passing name=value parameters
"""
Thus there are two forms to call this method:
If you have a mapping object map, such as REQUEST, you can call it by pm.manage_changeProperties(map).
If you have the values separately, you can use pm.manage_changeProperties(prop1=val1, prop2=val2, ...).
In fact, you can combine both ways (though the source documentation does not tell this to you): pm.manage_changeProperties(map, prop1=val1, prop2=val2, ...)
<dtml-call "manage_changeProperties(REQUEST)">We assume here, that manage_changeProperties is acquired and that the REQUEST object contains the new values for the properties.
Most management methods return an HTML page that is used as response when they are used from Zope's management interface. If you feel the need to call these methods directly, there is a high chance that you want to provide your own response page. Otherwise, your user will suddenly see Zope's management page. Thus, you are likely to discard the method's return value as is done by the DTML call command in contrast to the var command. A few management methods behave even worse. They perform a redirect to a management page. Such a redirect tells the browser to discard the response page and load the other page. When you observe such a behavior, you can counter it with a RESPONSE.setStatus(200) after the management method call.
The description above should tell you how to proceed when you feel the need to do management functions programmatically inside your Zope system. With the help of the ZClient, you can do this even from outside Zope in an external Python script or from the command line. ZClient, more precisely ZPublisher.Client, is a utility that helps you to call functions and methods via HTTP from a Python script. It can be used to automate arbitrary HTTP sites not just Zope sites.
The central facility defined by ZClient is the Function class. It provides a function interface for access to a given URL. Its constructor has the following synopsis:
url is the URL that should be used by subsequent calls of the constructed object in HTTP requests. HTTP requests against this URL can easily be performed by just calling the function object. arguments is a sequence of argument names. Because HTTP does not support positional arguments but only keyword arguments, positional arguments need to be mapped to keyword arguments. The parameter above provides the necessary names for this mapping. method is the HTTP request method to be used for calls. username and password provide the authentication information, in case the URL is protected. timeout is a placeholder for later timeout support. This parameter is currently not used, however. All other keyword parameters are passed into the constructor as the headers argument and used as HTTP headers for the requests.A function object f can later be call with the following synopsis:
i.e. with a sequence of positional followed by a sequence of keyword arguments. The names to be used to map positional arguments to keyword arguments have been defined by the arguments parameter to the constructor. It is not an error, if less positional arguments are given then there are defined names. The missing arguments are just not passed in the HTTP request. A call to a function object is transformed into an HTTP request. Arguments are converted to strings and, if necessary, properly encoded. File objects are transformed into file uploads. If the request was successful, its response is returned as a pair consisting of the HTTP response headers (a mapping) and the response body (a string). Otherwise a RemoteException is raised which can be catched and queried for all relevant information about the failing request.Client defines two wrappers around Function, the class Object and the function call. Object instances are local proxies for objects identified by an URL. The attribute access syntax obj.attributeName, can be used to access the attributes of the remote object. The result is not another Object instance[38] but a Function instance which can be called as shown above. The Object constructor supports the parameters url, method, username, password, timeout and **headers with a semantics similar to the corresponding parameters for the Function constructor. The function call supports the parameters url, username, password and arbitrary keyword arguments. It uses the explicitely named parameters to construct a Function object and then calls this with the remaining keyword arguments.
Example 3.27. Restarting Zope from an external script
from ZPublisher.Client import call
call('http://localhost:8080/Control_Panel/manage_restart', username='admin', password='x22qv?s.')
This small script will restart Zope when username and password
identify a user with the Manager role.
It will raise a RemoteException,
even if successfull, because Zope returns a 500
(Internal Server Error response when it
is shutdown or restarted over the Web.
Example 3.28. Packing Zope's object database
The file storage on which Zope's object database usually runs is essentially a transaction log file. When something changes, the modifications are appended to the file, but the old versions are not deleted. Over time, more and more old object versions accumulate and let the file grow. From time to time, the file needs to be packed to get rid of old, no longer used versions. This can be done over the management interface, but it is nice to be able to automate this via a periodic action scheduler such as CRON, the Unix action scheduler.
from ZPublisher.Client import call
call('http://localhost:8080/Control_Panel/Database/manage_pack', username='admin', password='x22qv?s.', days=30)
This script packs Zope's database by calling its database's manage_pack method and passing it the argument days=30. This will remove all non-current object versions that are older than 30 days.
Important
When you use such scripts, make sure that read permissions for them are restrictive. They often contain login information for users with special priviledges. People able to read the scripts can use this information to log in to Zope and use the priviledges.
An application of this technique is the program load_site. It supports mass imports from the file system into a Zope site. You find this utility in the utilities sub folder of your Zope distribution. You can look at its code for an advanced example of the technique.
5.3. FTP/WebDAV management
Zope has an integrated FTP server and supports WebDAV. This implies that you can explore the side with an FTP or WebDAV client, make modifications and, with some restrictions, create new objects. As there are tools that can virtually map FTP sides or WebDAV sites into your local file system, this provides for a very smooth integration into your usual working environment. There are two drawbacks, however: error messages are much less informative than they are through an HTML browser, at least for FTP management. This is because FTP only knows about very few error reasons and Zope's standard FTP support does not provide informative additional texts. Richard Jones posted a patch to Zope-dev that provides for better error information. I am not sure about WebDAV in this respect as I did not try this out. The second problem is the way how many tools operate on files in the file system: they implement changing a file by creating a new temporary file, write the modified content into it and then rename the file to the original which is deleted by that operation. This is nasty for Zope objects for two reasons: all information associated with the original object beside its content is lost: versions, history, meta-data[39] and the new object is often created with a wrong type. Tools implementing modification by creating a new object can therefore not be used to modify Zope objects mapped into the file system. Fortunately, many editing tools for Web content directly support FTP and/or WebDAV. In this mode, they often do not create temporary objects.
Both FTP and WebDAV can only create standard Zope objects. This is because they are designed to manage files but the objects in Zope are not simple files but have a finer grained structure. Zope implements a mapping from filename extensions to object types to create objects of the correct type. Of course, this mechanism can only create object types that it knows about; it will not create ZInstances or instances of application specific extensions. Again, this is hookable. If an object has or acquires an attribute PUT_factory, then this method is called with the parameters name, content_type and file_content: the name of the object to be created, the content type as determined either from the request's Content-Type header or guessed from the name extension, and the content of the uploaded file. If the method is able to determine the object type, it should return a new object of this type. Otherwise, it should return None. In this latter case, Zope's default factory is used which is based on name extensions and which creates a DTML Document if it is unable to determine the type.
Many modern Web editors support WebDAV, the Web Distributed Authoring and Versioning protocol. It was designed to enable safe concurrent authoring over the Inter/Intranet. As Zope supports this protocol, too, the editors can directly access, view and modify content inside Zope -- in the same way as if they were local files. Examples of such editors are Adobe's GoLive and Macromedia's DreamWeaver. Under Unix, the general purpose WebDAV client cadaver can be used. Different editors can plug in to become WebDAV enabled.
6. Security
The security subsystem has the task to prevent users from doing things they are not trusted to do. Such a task naturally falls into two subtasks: identify or authenticate the user and authorize authenticated users. We have already covered authentication. Zope supports HTML's basic authentication. Third party products provide cookie based authentication and can use a variety of user databases: e.g. NT, Unix passwd, LDAP, SQL tables. In this section, we look into authorization.
6.1. Permissions
Zope is an object oriented system. The primary operation in such a system is attribute access. Zope allows the access to any attribute with a non-elementary data type to be protected individually by a permission. A permission is an abstract entity without inherent semantics, it is represented by a string. Of course, this string should express the purpose of the permission, e.g. View management screens expresses (some kind of) management permission. Usually, a set of related attributes, often from different classes, are protected by the same permission: for example, View management screens protects the attributes manage, manage_menu, manage_top_frame, manage_page_header and manage_page_footer from class App.Management.Navigation and manage_cutObjects, manage_copyObjects, manage_pasteObjects from class OFS.CopySupport.CopyContainer, among others. Zope will prevent attribute access, if the current user does not have the required permission.
6.2. Roles
Zope does not associate permissions with individual users. This would make for too high a management overhead. Instead, Zope uses another abstraction, the role, to reduce the amount of permission association. A role abstracts several related tasks: for example, the Manager role is the culmination of all management tasks: creating user records, assigning roles and mapping roles to permissions, changing and controlling the site structure. On the other hand, the Editor role stands for all kinds of content work: changing, reviewing, releasing content. As with permissions, roles are abstract entities without intrinsic semantics. They are represented by strings. You can define your own roles, if this becomes necessary for your site.
6.3. Permission and role assignment
While an attribute can be protected only by a single permission, a user can have assigned any number of roles. Furthermore, you can give a role any number of permissions. Thus, you can, for example, assign to the Mr. Chief Editor the roles Editor and Supervisor. You can give to the role Editor the permissions addArticle and changeArticle while Supervisor gets the permission releaseArticle. Our example user will then indirectly have the permissions addArticle, changeArticle and releaseArticle.
When a user tries to access an attribute, it is checked whether the user has a role which in turn has the permission protecting the attribute. It he does not, an Unauthorized exception is raised. As we have seen, this triggers a login dialog.
Users and their roles are maintained by special Zope objects, so called User Folders. A User Folder is a collection of users and associated information. This information always includes the credentials necessary to authenticate a user, such as user name and password, and the user's roles. Third party user folders can associate additional information with users, such as email address, full name, address and so on.
The role assignment in the User Folder is global. This means, that the user has the assigned roles anywhere in the site that is governed by this User Folder[40]. Sometimes, you may want to assign a role only in a restricted context. For example, you may want to assign the Supervisor role to Mr. Chief Sports Editor only in the Sports folder. You could use a local role for this purpose. A local role is just a role that is not assigned globally, in the User Folder but only locally in the context of a given object (including its sub objects). Local roles are defined in the Security tab of the object's management screen.
The assignment of permissions to roles is also managed in the Security tab. This tab is essentially a big table with the rows corresponding to the permissions and the columns to the roles. The checkboxes in the table cells tell you and allow you to control whether the corresponding permission is granted to the corresponding role. The first column controls, whether permission assignments are inherited from the containing object. If checked, the checkboxes to the right provide additional grants, adding to that inherited from above. If unchecked, the permission is granted just to the roles specified by the checkboxes to the right; grants higher up in the hierarchy are irrelevant.
6.4. Proxy roles
Sometimes, it is necessary that a user can perform actions in a restricted context that he is not entitled to in general. For example, you will usually not allow anonymous users to call SQL methods as they could try to search for private information or even change your database. However, for registration purposes, it might be necessary that a yet anonymous user is able to write a user database record providing his personal information.
You can achieve this with a proxy role. A proxy role provides an object with alternative permissions during its "execution". Usually, an object is "executed" with the permissions of the user. However, if the object has proxy roles, the user's roles are irrelevant and "execution" uses the object's proxy roles.
Thus, to implement the user registration, you can restrict the permission Use Database Methods to the role Manager and give the registration action the proxy role Manager. This action would check the validity of the registration information and only use a database method to update the user database table if everything is okay.
As of Zope 2.2, proxy roles are no longer passed to called objects. Thus, if an object with proxy roles calls another object, then the called object is not executed with proxy roles, unless it itself has proxy roles defined. This provides for fine grained control over roles. In addition, proxy roles can both extend and restrict permissions, although this may not be of great practical importance.
Of course, proxy roles are managed through a corresponding tab in the management interface of objects for which they are applicable.
6.5. Owner restrictions
The security model described so far was essentially that of Zope before version 2.2. Then, it was discovered that it is very prone to Trojan Horse attacks.
In a Trojan Horse attack, the intruder drops a malicious object at an appropriate place. The object is malicious as it may try to do things, the intruder itself is not entitled to do, for example delete the complete Web site or (more likely) place (potentially) interesting but unwanted material into the entrance page. Of course, when the intruder executes the object itself, the malicious action is prevented by Zope's security system. If, however, the intruder achieves to somehow attract a user with sufficient authority to execute this object, it will perform its disastrous task.
Because Zope provides explicit control over error handling and sufficient introspection facilities, it was quite prone to such attacks. In a system without such features, the intruder's malicious object would probably have been discovered by the exceptions raised when a non-authorized user executes the object. In Zope, however, the intruder can simply catch these exceptions or even ask Zope whether he is entitled to execute the malicious operation and do it only, if Zope answers "yes".
From Zope 2.2 on, this security whole has been blocked. Most Zope objects, and all Zope objects a normal security sensible administrator would allow to be created by an untrusted user, have an Owner. When Zope executes an object, then it uses as effective permissions the intersection of the permissions of the object's owner and that of the current user. This almost removes the danger of Trojan Horse attacks, as even if the Trojan Horse object is executed by a user with very extensive permissions the execution can not do things, the intruder could not do directly. The danger has not completely vanished, though. If by some trick, the intruder is able to convince a trusted user to take over ownership of the object then it may perform its malicious work. However, this is much more difficult than trick him to view the object.
6.6. AUTHENTICATED_USER
The REQUEST object has an attribute AUTHENTICATED_USER that describes the current user. You can ask this object about the current user's name, his roles and potentially about additional attributes associated with the user, such as email address, real name, address and so on. The standard Zope user objects currently do not support additional attributes but third party user objects often do.
[4] In fact, extensions can add arbitrary new such classes. But we will not even look here at all types that come with the Zope core, just the most essential ones to start our project implementation.
[5] Sometimes, one speaks of a messages instead of a functions.
[6] We follow the Python terminology. What we call member is often called attribute and our attribute is often called feature.
[7] The ability of an object to persist, i.e. to live longer than the process that created it.
[8] The signature of a method is the sequence of formal parameters (their types, in a strongly typed system) and the type of its return value. In Java, the signature also includes the set of possible exceptions that can be raised by the method.
[9] The space is not a valid URL character. Nevertheless, Zope allows it. Try to avoid spaces, and if possible, also ~, , and .. They will make problem when you reference them in Python expressions.
[10] OFSP probably stands for Object File System Product.
[11] Note however, that many applications handle file modifications in a way which is not compatible with Zope's object model: they write the new content in a temporary file and then rename it. This will delete the old file. Inside Zope, the old object with its associated meta data and its versions is deleted. The new object has just the new modified content but not the other relevant information. Moreover, the type of the new object may be wrong. Do not use applications with this behaviour when Zope's objects are mapped into the local file system.
[12] There will probably soon be another XML based template type. It will allow visual template construction with XML, especially XHTML compatible visual editing tools. It will probably be based on the current HiperDOM product.
[13] Note that in Zope, the attribute or (more likely) the method do not need to belong to the object itself but can be acquired. External methods or Python scripts are often used to compute preprocessed values for indexing purposes. Note that DTML methods can usually not be used for this purpose, as ZCatalog calls them without parameters. Called this way, the DTML method does not have access to its context, especially not to the object for which it it is called, and therefore is not very useful.
[14] This is different than for field indexes, where a sequence implements an or search, i.e. the result is the union of the single results.
[15] It must not contain more than a single query.
[16] As I found out bitterly (Zope 2.3 and Zope 2.4), instances derived from Record do not have an instance dict and therefore cannot have instance members beside the record components. I hope, this will change in the future, as it makes these brain classes rather special: you will get an attribute error, whenever you try to add an instance member.
[17] They are rather (class level) attributes than methods. However, the other approach for attribute implementation, properties, does only allow simple types and never Zope objects. You should note, however, that a ZInstance is unable to override a method, whereas it is able to provide a new property value. Methods can therefore not be used to implement object level attributes, just class level attributes. You can let the ZClass inherit from Folder and use the folder content as complex object level attributes, if you need them (as we will do for our project).
[18] For unknown reasons, this is not completely true. The implemented interface PropertySheet is very similar to PropertyManager, with just a few minor additions. The two interfaces should be folded together.
[19] There are rumors that Zope has problems with the inheritance of ZClasses defined in other products. When such ZClasses are exported and later reimported, the relation to the original ZClass is lost. This means, modification of the inherited ZClass no longer affects the derived class. This would be a bug.
[20] I speak here of Zope 2.3.
[21] There is currently a project for Zope to get rid of this restriction. The project develops a new document template class based on XML. Each template is a well formed XML instance which may be an XHTML instance. Composition commands are provided by extension attributes, properly marked by an XML namespace. They may change the structure locally but let the macro structure unchanged. In this way, the templates can be designed and used as prototypes for the final generated pages. There is already a product called HiperDOM that serves as proof of concept and will be extended and refined for the new composition engine.
[22] Some browsers have the notion of default button and currently selected button. With these browsers, the user can activate a button through the keyboard, e.g. by pressing the RETURN key, rather than pressing it with the mouse.
[23] Some browsers optionally keep it forever.
[24] The implementing code is extremely (and unnecessarily) complex. I do not yet understand part of it. I am not sure, for example, whether the packagers list and record can not be used together. This would imply that the above statement is wrong. If you need such a feature, try it out. It may work.
[25] In fact, this conversion does nothing. I do not know, why it is there.
[26] Traversal may stop, too, if the current object is willing to take over the remaining path components. This is true, e.g. for PythonScripts.
[27] PUT requests may be exceptions.
[28] In general, all database operations are undone (unless the database does not support transactions) whether ZODB or external database operations. Other operations might not be undoable, as for example the sending of mail. The product developer can decide whether or not a product method uses the transaction framework and will be undoable. For some operations interacting with external systems, it is very difficult to make them undoable. Therefore, you should not be too disappointed or astonished, when they are not.
[29] A mapping is a set of items. Each item is a pair consisting of a key and a value. The mapping defines a map from keys to values. The value associated by a mapping m with a key k is denoted by m[k]. Mappings usually support methods keys, values, items, has_key with the obvious meaning.
[30] We assume a is an ExtensionClass instance and its attribute b an Acquisition.Implicit instance, such that acquisition is enabled. Furthermore, we speak of a's attribute with name b as the object b.
[31] This might not be true, if application specific traversal rules are in effect.
[32] A structured text is a text the structure of which is specified by empty line (paragraph separators), indentation and a few easy typographical conventions.
[33] The same should work for end tags, too. However, name arguments to end tags are apparently simply ignored. They also make no valid SGML.
[34] I think, this is a misfeature.
[35] I have filed a patch into the Collector, Zope's bug tracking system, that provides this information also in the last iteration of a batch. I was told the patch were integrated in Zope but apparently, it is not.
[36] I have filed a patch into the Collector, Zope's bug tracking system, that provides this information also in the first iteration of a batch. I was told the patch were integrated in Zope but apparently, it is not.
[37] This is only true, if the URL addresses a DTML object or a script.
[38] as it probably should be.
[39] Note that Zope objects are much richer than files.
[40] This is the subtree rooted in the User Folder's (site hierarchy) parent.